Reducing the Complexity of Information Retrieval by Weighted Querying
by Peter Vojtás and Jan Vinar
This report describes a project which was originally applied to information retrieval from traditional (deductive) databases, and is now being extended to Semantic Web sources such as XML, unstructured text, and heterogeneous and distributed sources. The aim of the project is to find effective ways of answering vaguely formulated queries on crisp, vague, uncertain or incomplete data.
This project has been running for several years at the Institute of Informatics of Safárik University in Kosice, Slovakia (a member of SRCIM) and involves a group of institute researchers aided by PhD and Masters students.
The aim of the project was to find ways of increasing the expressivity of querying languages by various means: using background knowledge to process both the queries (formulated in language that is as natural as possible) and the source material, introducing a similarity measure on the data domains as well as metadata, and introducing new logical operators such as weighted aggregation, which in turn leads to fuzzy or probabilistic data models.
While largely successful on the level of formal models and experimentation, this method was soon found to create a double combinatorial explosion. First, there was the data explosion: where a deterministic database consists of a well-defined subset of the Cartesian product of data domains, the fuzzy or probabilistic database should contain practically every element of that product (since its probability or truth value will be positive, though very small).
The second problem deals with the weighting process itself: to assess the probabilistic measure of a composite event consisting of n elementary events, it is in general necessary to evaluate 2n probability assignments for these events.
It might seem that the first problem at least could be solved by assigning a threshold value for inclusion in the database. However, it is non-trivial to determine what partial threshold values will lead to a desired threshold for a composite query (which is necessary if we look, eg for k best answers or the so-called e - best answer). This is merely difficult for fuzzy operators (due to their special nature-truth functionality), but practically impossible for probabilistic operators, unless we assume the independence of the elementary events in the question, and certain other restrictions.
Two ways for solving the threshold problem were followed in our research. The first way involves the definition and study of the fuzzy join of several tables and different methods of evaluating it were examined. The phenomenon of threshold propagation through the computational process was studied and various heuristics for choosing the order of join evaluation are now being empirically tested. The second method is based on a metric induced on the original attribute domains by a fuzzy linguistic variable. Consider (see the Figure for a very simple motivating example) the trapezoidal function 'sensible price'. The metric generating function shown in the figure assigns distance to each pair of prices. This is easily generalised to a distance between sets. In this way each record (whether with crisp or vague values) is mapped to a set of distances with respect to a given elementary query, and from that to a point in n-space, where scales of different axes correspond to weights of different attributes (determined by, for example, a neural network). For choosing the best points (with respect to the 'ideal' point located in the origin) several methods of computational geometry are available.
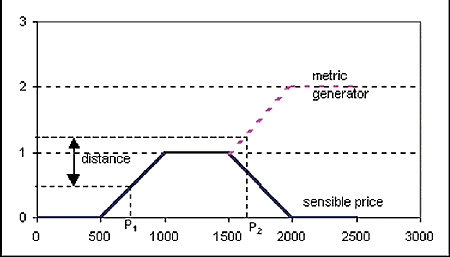 |
| Metric generation from linguistic variables. |
Other methods of inducing a metric on the original data are also possible, such as that of fuzzy conceptual lattices.
The notion of metric and the corresponding similarity measure has other uses related to IR. One of these uses is the result of applying the notion to data structure. Similar data structures are mapped automatically to a unifying metastructure allowing the collection of data from heterogeneous sources to a whole. This was explored by a group working within the project and led to the notion of the 'metadata-engine', which may find uses in data mining.
An interesting special case is the mining of data from independently created XML documents. As every author may create his own ontology to describe the meaning of his XML tags, it is first necessary to find a unifying ontology on the basis of detected similarities.
At present, the loose collaboration of groups and individual researchers that we have been calling a project is passing from the stage of formal models and promising experimental results to the formation of prototype software tools. This activity is largely being carried out in cooperation with member institutions of CRCIM, such as the Institute of Computer Science of the Czech Academy of Science, the Faculty of Mathematics and Physics of the Charles University and the Masaryk University. Also participating are our Spanish colleagues from the University of Malaga. The research reported here was partially supported by VEGA grant 1/7557/20.
Please contact:
Peter Vojtás, P. J. Safárik University, Kosice (SRCIM)
Tel: +421 55 62 209 49
E-mail: vojtas@kosice.upjs.sk
|



