

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by Carol Peters
MultiMATCH, a 30 month specific targeted research project under the Sixth Framework Programme, plans to develop a multilingual search engine for the access, organisation and personalised presentation of cultural heritage information.
Cultural heritage content is everywhere on the web, in traditional environments such as libraries, museums, galleries and audiovisual archives, but also in popular magazines and newspapers, in multiple languages and multiple media. The aim of the MultiMATCH project is to enable users to explore and interact with online accessible cultural heritage content, across media types and language boundaries.
The MultiMATCH search engine will be able to:
The concepts underlying the system are depicted in Figure 1. On the left-hand side of the figure, we show users querying the system in different languages for a range of information on the Dutch artist Vincent van Gogh, including critical analyses, biographies, details of exhibitions. The system displays the retrieved information in an integrated fashion, and in a format determined by the particular user profile. On the right-hand side, we show possible sources of this information and the ways in which it can be acquired.
 |
| Figure 1: The MultiMATCH idea. |
The project aims at developing a system prototype that can be demonstrated for at least four languages: Dutch, English, Italian and Spanish, and extendible to others. Figure 2 gives an idea of the workflow for the system development.
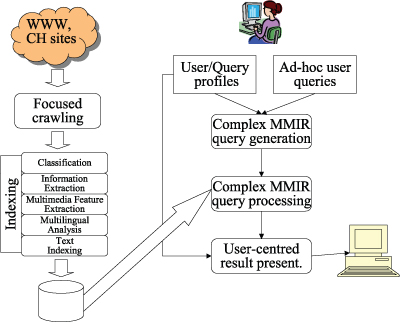 |
| Figure 2: Workflow for development of MultiMATCH search engine. |
The R&D work is organised around three activities:
The consortium comprises eleven partners, representing the relevant research, industrial and application communities. Each member will play a significant role in the design and development of the system, providing a part of the necessary know-how; the blend of competences will be a key factor for the success of the project. The six academic research partners (ISTI-CNR, U.Amsterdam, UNED-Madrid, U.Geneva, U.Sheffield, Dublin City U.) have already worked closely together collaborating in coordination of the Cross-Language Evaluation Forum (CLEF). CLEF focuses on stimulating advances in research in multilingual/multimedia information retrieval and on information extraction and user/system interaction in the cross-language context. The industrial partners, OLCC PICA, UK, and WIND, Italy will play a major role in the design of the system architecture and the integration of the various components, also with a view to the future industrialisation and commercial exploitation of the system. The cultural institutions, Casa de América, Spain, Alinari, Italy, and Sound and Vision, the Netherlands, each represent a different type of cultural institution with content in diverse media and languages but all three groups have in common the desire to improve and extend their information dissemination capabilities, and to work towards the development of standards for interoperability and metadata in the cultural heritage domain. The intention of these institutions is to be able to exploit the results of the project in their future information dissemination activities.
MultiMATCH is supported by the unit for Content, Learning and Cultural Heritage (Digicult) of the Information Society DG and is coordinated by ISTI-CNR, Pisa, Italy.
The project kick-off meeting was held in Pisa, 10-12 May 2006. The meeting was mainly dedicated to a detailed planning of the activities for the first year. The first system prototype is scheduled for release in November 2007. MultiMATCH will issue a quarterly newsletter providing information on the project activities, events and results. For further information, please see the project website.
Links:
http://www.multimatch.info
http://www.clef-campaign.org
Please contact:
Carol Peters, ISTI-CNR, Italy
MultiMATCH Project Coordinator
Tel: +39 050 3152897
E-mail: carol.peters![]() isti.cnr.it
isti.cnr.it
