

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by Alberto Del Bimbo, Marco Bertini and CarloTorniai
A research activity is under way at the Department of Informatics, Florence University, which aims at creating a framework for the automatic annotation of soccer videos and the semantic retrieval of videos based on highlights and other high-level concepts.
Effective usage of multimedia digital libraries has to deal with the problem of building efficient content annotation and retrieval tools. Video digital libraries require annotation at the level of pattern specification in order to retrieve multimedia content according to specific user preferences and high level semantic content description. We have implemented multimedia ontologies, which include both visual and linguistic concepts, showing how they can be used for video annotation and retrieval and for the creation of user interfaces that accept complex queries, such as the visual prototypes of actions, their temporal evolution and relations.
Broadcasters need tools to annotate their video asset archives in order to exploit them to produce better TV programmes, and to lower the costs of indexing and search. Usually the video annotation process is carried out manually, using predefined vocabularies and taxonomies defined by the TV archivists.
The basic idea behind multimedia ontologies is that the concepts and categories defined in a traditional ontology are not rich enough to fully describe the plethora of visual events that can occur in a video. In fact, although linguistic terms are appropriate to distinguish event and object categories, they are inadequate to describe specific patterns of events or video entities. We are investigating the representation of events that share the same patterns by visual concepts, instead of linguistic concepts, in order to capture the essence of the event visual development. In this case, high level concepts, expressed through linguistic terms, and pattern specifications, represented through visual concepts, can be both organized into new extended ontologies that couple linguistic terms with visual information.
Using visual prototypes it is possible to group different video clips according to their visual features and at the same time classify them according to the linguistic high-level semantic concepts related to the visual prototype.
We have implemented a multimedia ontology for the soccer domain. A simplified schema is shown in Figure 1. Visual concepts for the different subclasses of 'Shot on Goal' are shown. The ontology is expressed using the Web Ontology Language OWL so that it can be shared and used in a search engine to perform content-based retrieval from video databases or to provide video summaries.
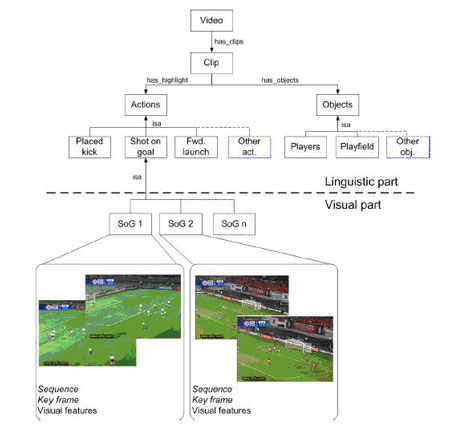 |
| Figure 1: Multimedia Ontology (partial view). |
The creation process of the multimedia ontology is performed by selecting a representative set of sequences containing highlights described in the linguistic ontology, extracting the visual features and performing an unsupervised clustering. The clustering process, based on visual features, generates clusters of sequences representing specific patterns of the same highlight, which are regarded as specialization of the highlight. Visual concepts for each highlight specialization are automatically obtained as the centres of these clusters. Reasoning on the ontology is used in order to refine the annotation according to temporal and semantic relations between events.
The Multimedia Ontologies Annotator is the framework that allows users to import basic ontology schemas, generate the multimedia ontology, annotate video clips according to the ontology, and perform complex queries in order to retrieve videos containing specific visual concepts and other high-level linguistic concepts. Figure 2 shows the interface of the Multimedia Ontologies Annotator.
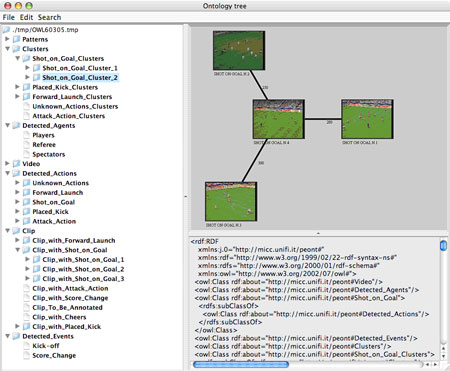 |
| Figure 2: Multimedia Ontologies Annotator Interface. |
It should be noted that users are able not only to browse, with a single interface, soccer and other video footage, but can also easily access the visual specifications of the linguistic concepts.
When users wish to see the different visual specifications of the linguistic concept 'Shot on Goal', they simply select the concept and the interface provides the clips that represent that concept. Moreover, a cluster view of similar visual concepts related to the linguistic concept is provided.
The queries that can be performed by the system involve both visual and high-level concepts. For instance a user can query for a sequence that starts with a forward launch, finishes with a shot on goal and contains a placed kick. He can also require that all actions are visually similar to a certain video clip or that all actions took place in a given location. The video produced should contain any type of attack action or placed kick visually similar to the selected models that occurred in soccer games played in the specified location.
Our future work will deal with the automatic generation of textual and vocal descriptions for video content based on visual features and temporal and semantic relations between concepts.
This work is partially supported by the Information Society Technologies (IST) Programme of the European Commission as part of the DELOS Network of Excellence on Digital Libraries.
Please contact:
Marco Bertini, University of Florence, Italy
Tel: +39 055 4796540
E-mail: bertini![]() dsi.unifi.it
dsi.unifi.it
Alberto Del Bimbo, University of Florence,
Tel: +39 055 4796540
E-mail: delbimbo![]() unifi.it
unifi.it
Carlo Torniai, University of Florence
Tel: +39 055 4237408
E-mail: torniai![]() micc.unifi.it
micc.unifi.it
