2-Days Ahead PM10 Prediction in Milan with Lazy Learning
by Giorgio Corani and Stefano Barazzetta
The lazy learning algorithm is used to predict PM10 air pollution levels in Milan, providing forecasts for the next two days with reasonable accuracy. In addition to the traditional data acquired by the air quality monitoring network, specific micrometeorological variables are algorithmically estimated and then used as input for our model.
Particulate matter (PM) is a mixture of particles that can adversely effect human health, damage materials and form atmospheric haze that degrades visibility. PM is usually divided up into different classes based on size, ranging from total suspended matter (TSP) to PM10 (particles less than 10 microns in aerodynamic diameter) to PM2.5 (particles less than 2.5 microns). In general, the smallest particles pose the highest human health risks. PM exposure can affect breathing, aggravate existing respiratory and cardiovascular disease, alter the body's defense systems against foreign materials, and damage lung tissue, contributing to cancer and premature death. Particulate matter includes dust, dirt, soot, smoke and liquid droplets directly emitted into the air by sources such as factories, power plants, cars, construction activity, fires and natural windblown dust.
The 'Air Sentinel' project, developed by the 'Agenzia Milanese per la Mobilità e l'Ambiente' (Agency for Mobility and the Environment, Milan, Italy), aims at publishing forecasts of pollutant concentrations in Milan. One-day statistical linear predictors for different measuring stations of PM10 have already been shown to provide satisfactory performances. These models compute a prediction of the daily PM10 average for the current day at 9 a.m.. Evaluation of these predictors via cross-validation on a yearly scale shows a true/predicted correlation higher than 0.85, and a mean absolute error of about 10mg/m3 (out of a yearly PM10 average of about 43mg/m3 ).
We have now developed a two-day predictor; ie, at 9 a.m. this model predicts the daily PM10 average for the following day. We use the lazy learning (LL) prediction approach by Bontempi et al. LL has been shown to be viable for nonlinear time series prediction and, in particular, also for air pollution prediction. The strengths of the lazy learning approach are its predictive accuracy, its fast design (the development of a LL model is much quicker than a neural network), the easy model update procedure, and the readability of the model structure. The most relevant contribution to LL development and diffusion in recent years has been probably done by the Machine Learning group working at the University of Bruxelles, which continuously produces LL algorithmic enhancements and applications, and also releases the LL implementation as open-source code.
The yearly average of PM10 in Milan is substantially stable (about 45 mg/m3) since the beginning of monitoring in 1998 and, just to give an idea of the severity of the phenomenon, the PM10 daily average exceeds the limit (50mg/m3 ) about 100 times every year. PM10 concentrations in Milan follow a typical weekly and yearly pattern: in particular, winter concentrations are about as twice as high as summer ones, both because of unfavourable dispersion conditions and of the additional emissions due to residential heating. Sunday concentrations are about 25% lower than the other days of the week, because of the reduction in traffic volumes.
Our PM10 prediction application requires a careful investigation of the suitability of several variables; in addition to the traditional data available from the air quality network (such as pollutant concentrations, wind speed and direction, temperature, atmospheric pressure etc., measured at the ground level), we also consider micrometeorological variables (such as mixing layer height, Monin-Obukhov length, etc.). These variables are algorithmically estimated and make it possible to characterize the dispersion conditions.
Results and Discussion
We present the results obtained by cross-validating the model. At each run, a year of data is used as the testing set in order to assess the ability of the model to predict previously unseen data. We compare the performances of the base model (whose inputs are PM10 (ie, autoregressive term), SO2, temperature and atmospheric pressure), with those of the model with micrometeorological data. The probability of detecting over-threshold values and the false alarm rate refer to a threshold value set at 50mg/m3.
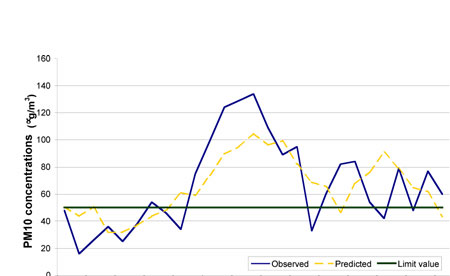
Provided that predictions of the model are available as a range of values, rather than as a crisp number, the forecast accuracy can be considered satisfactory, especially if micrometeorological data are used. Figure 1 provides a simulation sample for January 2003.
Links:
Website of the Machine Learning group at the University of Bruxelles: http://www.ulb.ac.be/di/mlg/
Repository of papers presented at the 9th International Conference on Harmonisation within Atmospheric Dispersion Modelling for Regulatory Purposes (Garmish, 2004), including the paper by Barazzetta and Corani dealing with 1-day ahead prediction of PM10: http://www.harmo.org/conferences/Proceedings/_Garmisch/Garmisch_proceedings.asp
Chapter dedicated to the air quality within the State of the Environment Report of Milan (published by Agenzia Mobilità e Ambiente): http://81.208.25.93/RSA/capitolo_3/main_capitolo.htm
Please contact:
Giorgio Corani, Stefano Barazzetta Agenzia Mobilità e Ambiente S.r.l., Italy
E-mail: giorgio.corani ama-mi.it, stefano.barazzettaama-mi.it
ama-mi.it, stefano.barazzettaama-mi.it