From Regression Testing to Regression Benchmarking
by Petr Tuma
Automated testing is widely used to detect regressions in software functionality during development. This is in contrast with the impromptu handling of regressions in software performance. The Distributed Systems Research Group in the School of Computer Science, Charles University, Prague, is working on extending regression testing to cover performance as well as functionality.
Regression testing is a proven and popular approach to meeting the demand for quality assurance during software development. In this process, a suite of tests is developed alongside the software so that the software can be regularly tested, and regressions in its functionality discovered and fixed. This, however, does not extend to regressions in performance, which are often orthogonal to functionality and consequently missed by regression testing.
Our current research focuses on remedying the existing neglect of performance in regression testing. We are building on the results of our past middleware benchmarking and comparison projects with industrial partners such as Borland International and IONA Technologies. We have designed a regression-benchmarking environment capable of providing extensive and repetitive testing for regressions in performance, dubbed regression benchmarking.
Distinguishing Traits
Regression benchmarking is a special application of benchmarking that is tightly integrated with the development process and is fully automated. Alongside the modules and supporting framework found in most benchmarks, the regression-benchmarking environment contains a results repository that keeps a history of results, and an analysis module that examines the history and detects regressions in performance. The architecture of such an environment is outlined in Figure 1.
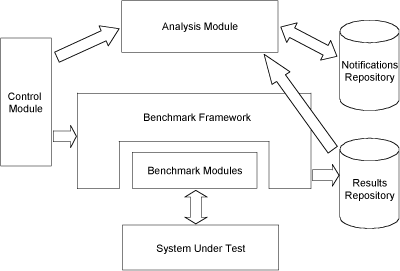 |
| Figure 1: Regression benchmarking environment architecture. |
Foremost in the features that make regression benchmarking different from benchmarking in general is the requirement that the former be fully automated. The automation requirement concerns both the benchmark execution and the results analysis.
The automated benchmark execution proves to be relatively simple, with the existing remote-access and scripting mechanisms being well up to the task. One problem associated with this is whether the execution time is short enough to allow the execution to run frequently. This puts demands on the ability of the environment to recognise, without undue delay, when the benchmark is producing stable data (as opposed to data distorted during warm-up) and when sufficient amount of data has been collected.
The automated results analysis has proven difficult, especially where precision is concerned. To minimise the cost of finding and fixing a source of a regression in performance, the environment must detect the regression as early as possible. This implies a need to identify minuscule regressions in performance that consist of a sequence of individually negligible changes over a long period of time. Such changes are hard to detect in typical benchmark results, which tend to have a variation in the order of several percent.
Developed Techniques
Our work on regression benchmarking follows two directions, which differ in the complexity of the distinct groups of benchmarks they consider. One looks at the group of simple benchmarks that test an isolated feature of the software under artificial workload, while the other considers the group of complex benchmarks that test a set of software features under a real-world workload. The distinction is important because simple benchmarks provide little space for interference and so yield precise results with straightforward interpretation, while complex benchmarks exercise multiple functions of the software concurrently and therefore provide room for results to be influenced by complex interactions among the functions.
With simple benchmarks, we primarily strive to minimise variation among results. We design the benchmarks to measure short operations and express the results using robust estimators that are not affected by a small number of exceptional observations. This minimises the probability of any interference that would increase the variation of the results. While the variation is reduced, it is not altogether removed. This prevents performance regression being detected through a direct comparison of the results. We continue by interpreting the results as a sequence of independent identically distributed observations of a random variable, and compare the results using common statistical tests for comparing samples from two populations, as illustrated in Figure 2.
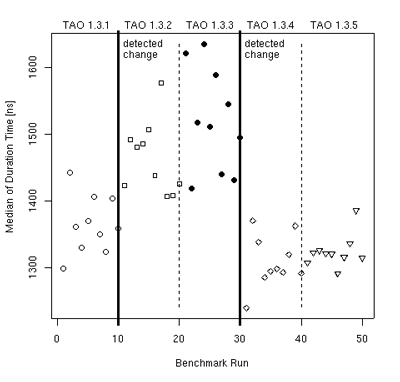 |
| Figure 2: Change detection in simple benchmark results. |
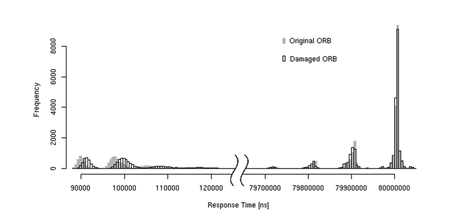 |
| Figure 3: Clusters in complex benchmark results. |
For complex benchmarks, we cannot easily minimise variation of the results, which is significantly larger than with the simple benchmarks. This prevents not only a direct comparison of the results, but also the use of the common statistical tests, which provide only weak results. We tackle this problem by interpreting the results as a union of clusters that can be compared one–by–one, using the traditional iterative clustering algorithms to separate the results into clusters (see Figure 3). Further work on the algorithms is required to avoid the need for manual hints and other input, which is incompatible with the regression benchmarking.
Links:
http://nenya.ms.mff.cuni.cz/projects.phtml?p=mbench
Please contact:
Petr Tuma, Charles University/CRCIM, Czech Republic
Tel: +420-221914267
E-mail petr.tuma mff.cuni.cz mff.cuni.cz
|


