|
|
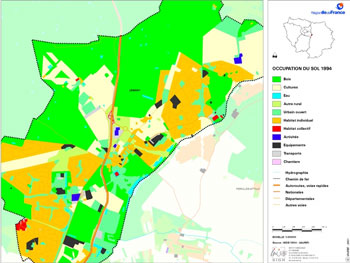
Central to the analysis was the notion of repository semantics: the set of statements that one would like to make about the images in the repository, and which form the basis for retrieval queries. In the absence of such a semantics, the retrieval problem is ill-defined, since we literally do not know what we wish to retrieve. (In particular, this applies to the use of query-by-example.) In the presence of such a semantics, the notion of evaluation via retrieval performance, although well-defined, becomes redundant: if the image processing engine used in the retrieval system can reproduce the semantics, accurate retrieval can be achieved. Unfortunately, specification of the semantics is very hard for many databases. In this respect, our two reference collections differ fundamentally. In the IGN collection, a semantics for the queries likely to be made of a retrieval system is available in the form of land use maps compiled by the Institute for Urban Planning and Development of the Paris Ile-de-France Region (IAURIF). An example is shown in Figure 2.
Evaluation for this collection is thus straightforward: the more accurately an image processing engine can reproduce this ground truth, the better will be the retrieval performance. On the other hand, the BAL images possess a very complicated semantics, even if we consider only statements for which there exists consensus, such as "the image in Figure 1 contains two people", and ignore artistic and emotional judgements. There is little hope of making this semantics both explicit enough to be used for evaluation and simultaneously broad enough to cover a significant part of the semantics of the collection. In this case, can anything be said about how well a retrieval system or the image processing engine that powers it might perform? It is clear that the semantics associated with the BAL images will at least involve the identification of areas in the images corresponding to different 'objects'. This implies that the output of image segmentation algorithms, which split the image area into a number of disjoint pieces, may capture a reduced and implicit portion of the full semantics and therefore could provide the first stage of the image processing engine for a future retrieval system for the BAL database. Following the reasoning above, an evaluation of the semantic content of these methods then gives an indication of the potential success of retrieval systems based on them. However, since the methods make no explicit semantic statements about the images, no direct comparison of output with semantics is possible. The alternative is to use a psychovisual test with human subjects to compare the semantic content of different segmentation methods, and consequently this was the methodology followed in MOUMIR. The test was designed to answer two questions. First, in the environment of this reduced and implicit semantics, does a consensus about a 'best' segmentation exist? Second, if a consensus exists, what do we learn about the value of different segmentation methods for retrieval? The test worked as follows. First, a subset of the images in the BAL database were segmented using a number of segmentation algorithms of different types. Each subject was then given a series of trials, in each of which they were shown a screen like that in Figure 3. In the centre of the screen was the original image, while on either side were the results of two segmentation algorithms. Each result was displayed in two different ways: the boundaries of the regions above, and the regions themselves below. The subject was told to click on the side of the screen that contained the segmentation that 'made most sense'. If undecided, they could click in the centre. The choice and the time taken to make it were recorded, the latter being used as a measure of the 'certainty' of the judgement.
The results give a pairwise ordering of the segmentation methods involved, since they are tested two at a time. It is a first sign that a consensus exists that the pairwise ordering is consistent with a single total ordering on the methods. Quantitative statistical tests confirm that the results are not due to chance, thus implying that there is some subject-independent sense in which one segmentation is better than another, at least for this image collection. Of further interest is the fact that the two schemes that performed best were more or less tied, while at the same time being the least and the most complex of the methods tested. The first split the image into areas of approximately equal grey level, while the second used complex colour and texture models. This seems to confirm the folklore that intensity edges, as captured by the first model, are as important as, but no more important than the colour and texture information captured by the second model, but further investigation is needed to analyse the reasons why these schemes performed so well. The work described above was performed in collaboration with Nick Kingsbury and Cián Shaffrey of the Cambridge University Engineering Department Signal Processing Laboratory. A research report (INRIA RR4761), and publications resulting from this work, are available at the author's home page and on the MOUMIR web site, reached via the links below. Links: Please contact: |
|
|