| |
AmbientDB: P2P Database Technology for Ambient Intelligent Multimedia Applications
by Peter Boncz
Applications providing intuitive and proactive access to heterogeneous multimedia collections are an important part of the vision of ambient intelligence. CWI has tackled the problem of bridging the gap between such applications and multiple diverse sources of multimedia content using the paradigm of peer-to-peer (P2P) database technology.
Ambient Intelligence refers to digital environments in which multimedia services are sensitive to people's needs, personalised to their requirements, anticipatory of their behaviour and responsive to their presence. Some obvious examples are playing music appropriate to the situation, the location (at a party, in the car) and the mood (stressed, happy), or showing pictures relevant, for instance, to a holiday being discussed. Such audio and video content will be pervasively available in highly distributed multimedia databases found on the Internet (itunes.com), in our homes (PC, TiVo) and cars, and in a mobile form (phones, portable media players).
We envision an environment in which media-rich and intelligent end-user applications run on mobile devices such as PDAs and smartphones. These devices connect in P2P fashion with other devices in the neighbourhood, sharing multimedia content and associated meta-data, as well as context data (temperature, light, mood, persons present) stemming from both sensors within the devices and external environmental sensors.
In such a scenario, heavier (non-mobile) semantic multimedia servers that hold and index large multimedia collections may be found on the Internet or in local base stations. Such servers extract features and context data from multimedia objects, and perform off-line indexing and data-mining operations on these, while offering on-line multimedia retrieval services. Such services might allow, for example, nearest neighbour top-N queries on video data using probabilistic frameworks such as Gaussian mixture models.
An important problem in realising ambient intelligent applications is how to exploit all these possible data sources and services. Clearly it is undesirable to hardcode all context and content information management facilities in each application. Such an approach is inherently static, generates a tremendous duplication of effort among applications with overlapping functionalities, and ignores the crucial need for applications to dynamically share both content and context information in order to interact intelligently with each other. Consequently, there is a need for an adaptive and resource-aware middleware layer that shields such applications from these complexities.
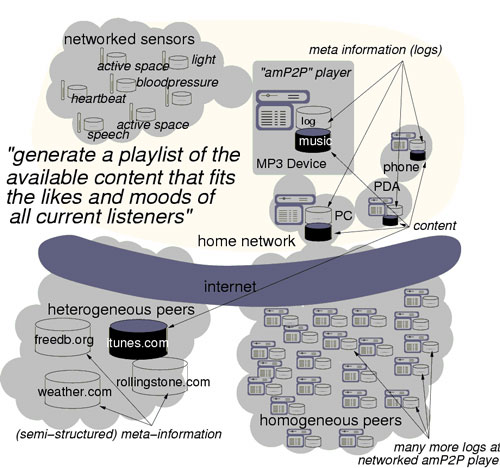 |
| Scenario: "generate a playlist of the available content that fits the likes and moods of all current listeners". |
The premise of the AmbientDB project is that this middleware role of integrating context-awareness and access to distributed multimedia retrieval servers could be handled by P2P database technology. Such technology allows devices to self-organise in ad-hoc overlay networks, without the need for central coordination. The principal functionalities it aims to provide are:
- ad-hoc integration of possible diverse information sources into a global schema. This concerns both integration of data access as well as services (queries) supported on this data by the participating peers
- facilities for ad-hoc query execution over this integrated global schema. By using high-level query languages, applications can concentrate on the issue of 'what' to ask, while the database technology concentrates on 'how' to execute such requests in an optimal manner
- a framework for expressing diverse replication, and update/ synchronisation strategies.
One important research question in AmbientDB is which data model and query formulation framework is sufficient to support non-trivial semantic multimedia retrieval queries. The fact that AmbientDB target devices may be mobile and are frequently disconnected, also opens up questions as to alternative update propagation frameworks that can, for example, aim at convergence rather than pure transactional serialisation. Additionally, we look at formalisms that allow expression of application-specific (loose) consistency constraints, replication mechanisms and conflict resolution strategies, using tools such as gossip protocols. Finally, query execution in an ad-hoc network of highly heterogeneous devices poses a number of resource optimisation challenges, which form the current focus of our research.
The AmbientDB project started in the summer of 2002 at the INS1 group of the Information Systems cluster at CWI. This group researches novel database architectures and their integration into advanced application areas, in particular semantic multimedia retrieval. We focus on the area of multimedia in advanced consumer environments, and cooperate in this area with Philips Natlab, which is looking at P2P database techniques to provide integrated data managements for its future generation of networked consumer electronics. This cooperation is part of the MultimediaN national Dutch knowledge infrastructure project. In particular, Twente University will use AmbientDB as its vehicle for a semantic context-based query tool in this project. The MultimediaN project is expected to start in the winter of 2003 and run through to 2007.
Links:
http://www.cwi.nl/~boncz
http://www.cwi.nl/ins1
http://db.cwi.nl/rapporten/abstract.php?abstractnr=1355
Please contact:
Peter Boncz, CWI
Tel: +31 20 592 4309
E-mail: boncz@cwi.nl
|


