Hybrid Caching of Search Engine Results
by Tiziano Fagni and Fabrizio Silvestri
The High Performance Computing Lab of ISTI-CNR in Pisa, has developed an efficient caching system aimed at exploiting the locality present in the queries submitted to a Web search engine. The cache adopts a novel hybrid strategy, according to which the results of the most frequently submitted queries are maintained in a static cache of fixed size, and only the queries that cannot be satisfied by the static cache compete for the use of a dynamic cache.
Caching is a very effective technique to make a service that distributes data/information to a multitude of clients scalable. As suggested by many researchers, caching can be used to improve the efficiency of a Web Search Engine (WSE). This is motivated by the high locality present in the stream of queries processed by a WSE, and by the relatively infrequent updates of WSE indexes that allow us to think of them as mostly read-only data.
The architecture of a modern WSE may be very complex and includes several machines, since a query may require various sub-tasks to be executed. For example, a large and scalable WSE, which is typically placed behind an http server, is usually composed of several searcher modules, each of which preferably runs on a distinct machine and is responsible for searching the index relative to one specific sub-collection of documents. Of course, in front of these searcher machines there is a mediator/broker, which collects and reorders the results of the various Searchers, and produces a ranked vector of the most relevant document identifiers (DocIDs), eg a vector usually composed by 10 DocIDs. These DocIDs are then used to get the associated URLs and page snippets included in the html page returned to the user through the http server (see Figure 1).
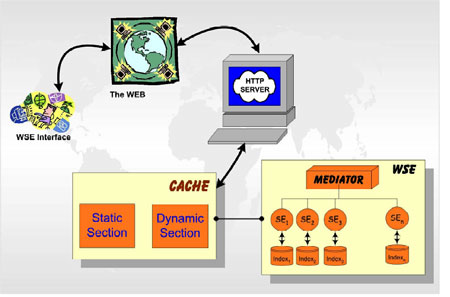 |
| Figure 1: The caching system architecture and its positioning within a typical distributed WSE environment. |
On the basis of an accurate analysis of the locality present in three large query logs, we designed and implemented a novel hybrid caching strategy where the results of the most frequently accessed queries are maintained in a static cache of fixed size, which is completely rebuilt at fixed time intervals. Only the queries that cannot be satisfied by the static cache compete for the use of a dynamic cache.
The superiority of our hybrid strategy over purely static or dynamic caching policies was demonstrated by several experimental tests, conducted to measure the cache hit-rate as a function of the size of the cache, the percentage of static cache entries (f_static), and the replacement policy (LRU, LRU2, LRU2S, 2Q, FBR) used for managing dynamic cache entries. Figure 2 shows the cache hit rate obtained on the largest of our query logs by using different replacement policies as a function of the ratio between static and dynamic cache entries. As it can be seen, our hybrid caching strategy always outperforms purely static and dynamic policies.
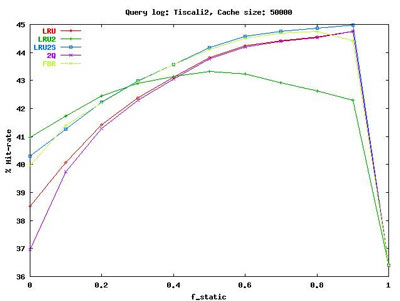 |
| Figure 2: Hit rate obtained on a large query log by using different replacement policies as a function of the ratio between static and dynamic cache entries. |
Moreover, we showed that WSE query logs exhibit not only temporal locality, but also a limited spatial locality, due to the presence of requests for subsequent pages of results. While most user searches are satisfied by the first page of results returned by the WSE, about 10% of searches are less focused and require additional pages. Our caching system exploits this user behavior by anticipating the requests for the subsequent pages by means of an adaptive prefetching heuristic that improves the hit rate achieved and, at the same time, limits the additional loads on the core query service of the WSE. Figure 3 shows the improvement on the cache hit rate for different prefetching factors as a function of the ratio between static and dynamic cache entries. While caching reduces the load over the core query service of the WSE and improves its throughput, prefetching aims to increase the cache hit rate and thus the responsiveness of the WSE.
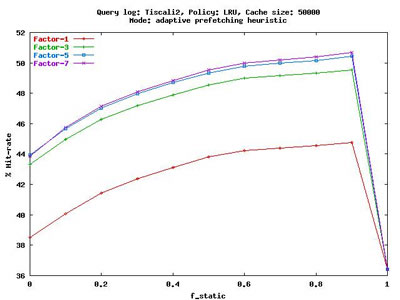 |
| Figure 3: Hit rate for different prefetching factors as a function of the ratio between static and dynamic cache entries with adaptive prefetching. |
Finally, differently from other work in this field, we evaluated cost and scalability of our cache implementation when executed in a multi-threaded environment. Our hybrid cache implementation resulted very efficient due to the accurate software design, and to the presence of the read-only static cache that reduces the synchronizations between the multiple threads concurrently accessing the cache (see Figure 4).
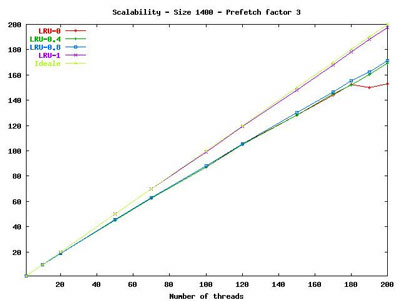 |
| Figure 4: Scalability of the caching system as a function of the number of concurrent threads used. |
Please contact:
Fabrizio Silvestri, ISTI-CNR
Tel: +39 050 315 3011
E-mail: fabrizio.silvestri@guest.cnuce.cnr.it
|


