| |
SOMLib - New Approaches for Information Presentation and Handling
by Andreas Rauber
While tools exist that allow us to search through vast amounts of text within seconds, most systems fail to assist the user in getting an overview of the information available or maintaining orientation within an information space, and fail also to convey meta-information in an intuitively graspable way. SOMLib is a digital library system addressing these issues by providing automatic content-based organisation and metaphor-graphics-based visualisation facilitating exploration and understanding of information spaces.
With the increasing availability of information in electronic form, be it online magazines, legal or medical document databases, project archives, or documentation on a company-internal intranet, advanced digital library systems that support users in interacting with large information repositories are gaining in importance. Yet, while databases and search engines help us in retrieving snippets of information, current tools fail to provide us with a feeling of 'where' information is available, and how different facts relate to each other. The ability to keep an overview of factors such as the information available, the topics covered by a given site and the amount of information available on a given topic is only poorly supported. In addition to the powerful search methods offered by modern information systems, it seems difficult to provide equally powerful means of organising and structuring the information.
What we would like are ways of information organisation and representation that allow us to make use of the concepts that we are using constantly, unconsciously, when handling and navigating real-world information spaces. Libraries, bookstores, project documentation in binders, working material and paper collections are all conventionally organised (also) by thematic criteria. This allows us to immediately get an overview of which kind of information is available in which section of an archive, how many reports have been filed on a specific topic in a binder, and so on. Due to the spatial location it is also easier to find a paper, report etc for the second time, as it is easier to recall roughly where a given document was located than to remember sufficiently precise search criteria, or its relative position within a listing.
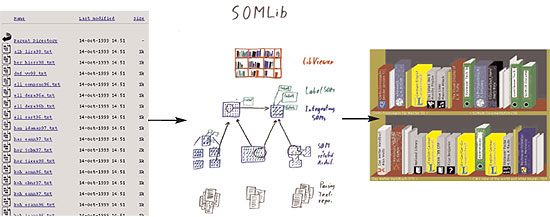 |
| The SOMLib system: from text collections via content-based organisation, to metaphor-graphics-based representation of document repositories facilitating intuitive browsing and exploration. |
With the SOMLib digital library, we created a system providing content-based organisation of document repositories, facilitating intuitive browsing and exploration of the information space. It builds on and incorporates works in the fields of information retrieval, neural networks, information visualisation, and usability analysis.
Low-level features based on word frequencies are extracted from the text to provide a domain- and language-independent content representation of text documents in a high-dimensional vector space. The 'self-organising map' (SOM), a popular unsupervised neural network model, is further used to cluster the document feature vectors, performing a topology-preserving mapping of the documents from the high-dimensional vector space onto a two-dimensional map space. Documents are thus grouped according to their mutual similarity, having documents on similar topics mapped onto neighbouring locations on the map. Using the 'growing hierarchical self-organising map' (GHSOM), a novel extension of the SOM, we can further detect subject hierarchies in a document collection, with the neural network adapting its size and structure automatically during its unsupervised training process to reflect the topical hierarchy. Individual SOMs can further be integrated to form a network of referencing maps.
By mining the weight vector structure of the trained maps using the 'LabelSOM' technique, the system automatically extracts keywords describing the various topical clusters. This is based on the analysis of the feature distributions within each cluster. It helps users in identifying which topics are present in a given document collection and where they are located on the map.
Finally, the 'libViewer' provides an intuitive representation of the documents in a repository by using real-world metaphors such as different document types, spine widths, dust etc to convey metadata in an intuitively graspable way.
Using the 'SOMLib' system, users can browse a document collection in the form of bookshelves and find clusters of documents on similar topics located in neighbouring boxes, with the topic of each box being described by a set of automatically extracted keywords, and metadata being depicted in the form of different document representations. In combination with conventional approaches for searching and dynamically sorting text archives we thus have a powerful tool at our disposal, which allows us to obtain and maintain an overview of the amount and type of information available, and to detect relationships between different documents. This means we can better handle, interact with, and use the available information.
The 'SOMLib' system has been applied in numerous different domains in a variety of languages, such as the organisation of legal databases, newspaper archives, scientific document collections and Web search results. Recently, the principles of this work have been expanded for use in digital music archives as part of the 'SOM-enhanced Jukebox' (SOMeJB) system. By analysing frequency spectra of audio files and transforming them to time-invariant representations while incorporating psycho-acoustic models, organisation and exploration following musical genres is facilitated.
Andreas Rauber is currently an ERCIM Research Fellow at INRIA.
Please contact:
Andreas Rauber, Vienna University of Technology
E-mail: rauber@ifs.tuwien.ac.at
http://www.ifs.tuwien.ac.at/~andi
|


