ERCIM News 64January 2006Contents 
This issue in pdf Subscription Archive: Next issue: April 2006 Next Special theme:
|
by Stanislav Mikeš and Michal Haindl
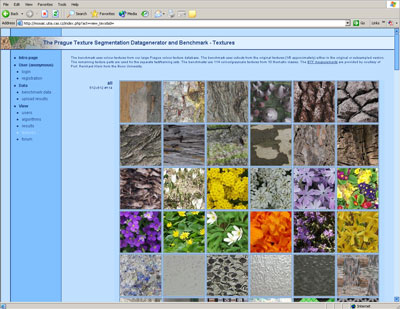
The Prague texture segmentation data-generator and benchmark is a Web-based service developed as a part of the MUSCLE Network of Excellence. It is designed to mutually compare and rank different texture segmenters and to support new segmentation and classification methods development. It can be easily used for other applications such as feature selection, image compression, and query by pictorial example.
Unsupervised or supervised texture segmentation is the prerequisite for successful content-based image retrieval, automatic acquisition of virtual models, quality control, security, medical applications and many others. Although many methods have already been published, this problem is still far from being solved. This is partly due to the lack of reliable performance comparisons between the different techniques. Rather than advancing the most promising image segmentation approaches, researchers often publish algorithms that are distinguished only by being sufficiently different from previously published algorithms. The optimal alternative is to check several variants of a method being developed and to carefully compare results with the state of the art. Unfortunately, this is impractical, since most methods are too complicated and insufficiently described to be implemented with acceptable effort. We were facing similar problems during our texture segmentation research, and for this reason we implemented a solution in the form of a Web-based data generator and benchmark software.
The goal of the benchmark is to produce a score for an algorithm's performance. This is done so that different algorithms can be compared, and so that progress toward human-level segmentation performance can be tracked and measured over time. The benchmark operates either in full mode for registered users (unrestricted mode - U) or in a restricted mode. The major difference is that the restricted operational mode does not store a visitor's data (results, algorithm details etc) in its online database, and does not allow custom mosaics creation. To be able to use the complete and unrestricted benchmark functionality, registration is required.
The benchmark allows users to:
Benchmark datasets are computer-generated random mosaics filled with randomly selected textures. Both generated texture mosaics and the benchmarks are composed from the following texture types: (i) monospectral textures (derived from the corresponding multispectral textures), (ii) multispectral textures, and (iii) BTF (bi-directional texture function) textures.
|
|
The benchmark uses colour textures from our Prague colour texture database, which contains over 1000 high-resolution colour textures categorized into ten thematic classes. The benchmark uses cut-outs from the original textures (1/6 approximately) either in the original resolution or a sub-sampled version. The remaining parts of the textures are used for separate test or training sets in the benchmark-supervised mode. The benchmarks use 114 colour/greyscale textures from ten classes. The BTF measurements are provided courtesy of Prof. Reinhard Klein from Bonn University.
Colour, greyscale or BTF benchmarks are generated upon request in three quantities (normal=20, large=80, huge=180 test mosaics). For each texture mosaic the corresponding ground truth and mask images are also included. The test mosaic layouts and each cell texture membership are randomly generated, but identical initialization of the corresponding random generators is used, so that the requested benchmark sets (for the same size and type) are identical for each visitor.
The submitted benchmark results are evaluated and stored (U) in the server database and used for the algorithm ranking according to a chosen criterion. We have implemented the most frequented nineteen evaluation criteria categorized into three groups: region-based (5), pixel-wise (12) and consistency measures (2). The performance criteria mutually compare ground truth image regions with the corresponding machine-segmented regions. The region-based criteria are correct, over-segmentation, under-segmentation, missed and noise. Our pixel-wise criteria group contains the most frequented classification criteria such as omission and commission errors, class accuracy, recall, precision etc. Finally the last criteria set incorporates the global and local consistency errors. The evaluation table is re-ordered according to the chosen criterion. For each compared algorithm there is a concise description available, eg author, algorithm details, BIB entry and WWW external page.
Links:
http://mosaic.utia.cas.cz
http://www.utia.cas.cz/RO
BTF measurements (courtesy of Prof. Reinhard Klein): http://btf.cs.uni-bonn.de/index.html
Please contact:
Stanislav Mikeš, Institute of Information Theory and Automation, Academy of Sciences / CRCIM, Czech Republic
Tel: +420-266052350
E-mail: xaos![]() utia.cas.cz
utia.cas.cz