| |
Opponent Models in Games
by Jeroen Donkers and Jaap van den Herik
The Institute of Knowledge and Agent Technology (IKAT) of the Universiteit Maastricht is well known for its research in game-playing programs. An important domain of investigation is the development of methods that allow the use of opponent models. In contrast to human beings playing games such as Chess or Checkers, most computer programs that play these games do not take into account the peculiarities of an opponent. By introducing opponent models, computer game-playing becomes more human-like, thereby improving their artificial intelligence.
The use of opponent models is a practice that even children can master. The game of TicTacToe provides a good illustration. At a certain age, a child learns that the game can best be played using a set of four rules (two knowledge rules and two heuristic ones). The two knowledge rules are: (1) make three-in-a-row, if you can, and (2) prevent the opponent from making three-in-a-row, if there is such a threat. The heuristic rules are: (3) take the middle square if it is unoccupied, and (4) take a corner square, if it is unoccupied. This strategy offers the child an advantage over other children who are still unaware of it. However, when time passes, all other children will have learned the strategy and games tend to end in a draw. At a certain point in time, the child will discover that if the opponent uses the strategy of the four rules, it can be exploited. The move sequence in the figure illustrates this clearly.
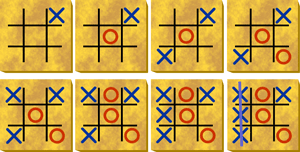 |
| Cross knows that Circle adheres to the strategy of the four rules. |
In game-playing it is often assumed that the opponent has a similar (though opposite) goal and uses a similar strategy. This assumption has led to the development of the famous Minimax procedure by John von Neumann in 1928. Since the arrival of modern (fast) computers, a large number of very efficient algorithms have been developed on the basis of this procedure as well as many enhancements (such as a-b Search), resulting in computers playing Chess at world champion level or even better. There are, however, situations in which the Minimax (a-b) procedure does not lead to the best possible play because it does not use any knowledge of the actual opponent.
From the beginning of game-playing by computers (in the 1950s), several methods have been proposed that incorporate knowledge of the opponent, but none of these methods were ever applied successfully. In 1993, two research groups (Technion in Haifa, Israel and IKAT in Maastricht, The Netherlands), simultaneously and independently invented a method, called Opponent-Model Search (OM Search), which incorporates an explicit model of the opponent. A strong prerequisite of this method is that it requires a highly accurate opponent model - basically, the method requires explicit knowledge on how the opponent evaluates every position in the game. It makes the method hard to apply in practice. Since then, several variants of the method have been proposed and deeply investigated. One of these variants was developed in 2000 at IKAT and is called Probabilistic Opponent-Model Search (PrOM Search). PrOM Search uses an extended opponent model that includes uncertainty on the opponent. The uncertainty in the model allows it to be successful even with less strict knowledge of the opponent than in the case of (pure) Opponent-Model Search.
The two search methods (OM Search and PrOM Search) are further investigated to find out to what extent and under which conditions they are successful. We mention two issues that involve the risk of speculating on an opponent's strategy. The first issue is that the opponent model used can be wrong (even at one point) - which may lead to bad predictions of the opponent's moves. Bad predictions can lead to wrong decisions and eventually to losing a game. This means that much effort must be put in obtaining a reliable opponent model. The second issue is that the own evaluation of a game position can be wrong. This can include the overestimation of a position that the opponent assesses correctly. In such a case, OM Search (and to a lesser extent PrOM Search) will be attracted to the overestimated position, causing bad play, even if the opponent model is correct. A condition, called admissibility, has been defined that prevents the occurrence of such attractor positions.
We applied OM Search and PrOM Search to several games (eg, Chess, Lines of Action, and Bao) and discovered that the methods can be successful, albeit under severe prerequisites. The highest expectations come from PrOM search, but the computational costs of this method are rather expensive.
The next step is to apply the successful methods to games in which both players have an opponent model, ie, they are aware of each other's strategy. This might be a more realistic setting than the asymmetrical OM search. Moreover, it enables the identification and utilisation of particular subgoals of both players and a new algorithm can be applied to make use of common interests.
Link:
http://www.cs.unimaas.nl/~donkers/games/omsearch
Please contact:
Jeroen Donkers, Universiteit Maastricht, The Netherlands
Tel: +31 43 3883481
E-mail: donkers cs.unimaas.nl cs.unimaas.nl
|


