Fluid Computing
by Marcel Graf
It has long been desirable to be able to let an application 'flow' from one user interface to another, depending on the user's situation and the capability of the interface being used. The IBM Zurich Research Laboratory has developed middleware which realises this wish. The service provided is called Fluid Computing.
Fluid Computing is a sub-area of Pervasive Computing. It denotes the replication and real-time synchronisation of application states on several devices. Thus the application state flows as a 'fluid' between devices.
There are three main application areas:
- Multi-device applications: several devices may be temporarily coupled to behave as one single device, for example, a mobile and a stationary device.
- Mitigation of the effects of variable connectivity: applications on ubiquitous devices can exploit full or intermittent connectivity, or operate in disconnected operation - all in a seamless fashion.
- Collaboration: multi-person applications enable several users to collaborate on a shared document in synchronous mode (at the same time) or in asynchronous mode (at different times) without the user having to switch the application.
The Fluid Computing middleware replicates data on multiple devices and achieves coordination of these devices through synchronisation. Each device has a replica of the application state, which allows it to operate autonomously. A synchronisation protocol tries to keep the replicas consistent, depending on the quality of the network connectivity available (weak consistency). The Fluid Computing synchronisation protocol operates in two modes. Batch mode replication occurs when connectivity is regained after disconnection, exchanging all updates that have accumulated during the disconnection. Trickle mode replication occurs as long as there is some connectivity, propagating updates in real-time as soon as they are generated at a replica.
The weak consistency approach enables disconnected operation: we want to allow the user to continue working with a device and making updates even when the device has no connectivity. Replicas are therefore allowed to become inconsistent when disconnected. The propagation of updates for synchronisation has two special properties, explained below.
Epidemic update propagation: A user who carries several devices (mobile phone, PDA, watch etc) will often be in a situation in which the devices have connectivity between one another via a wireless proximity network (eg Bluetooth), but no wide-area connectivity. We want to be able to use the proximity connectivity to make the devices consistent among themselves. Updates can thus be exchanged with any other replica, may even propagate through several other replicas, and are not required to go through a central server.
Real-time update propagation: Mobile devices are limited in their human/computer interaction capabilities because of their small size. This problem can be overcome by temporarily coupling several devices tightly via a wireless proximity network. Tight coupling means that a user action (eg a keystroke) on one device is immediately reflected on the other devices, such that the user experience is that of a single device. This enables the combination of devices to be optimised for a certain input or output modality, for example, the combination of a mobile phone with a large stationary display. Therefore when there is connectivity between a set of replicas, and the user performs an update, this update is sent immediately to the other replicas. The replicated application state allows a user to decouple devices at any time without breaking the application.
 |
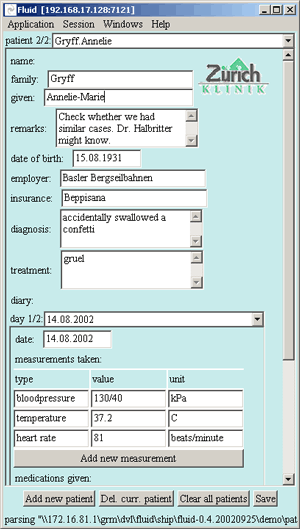 |
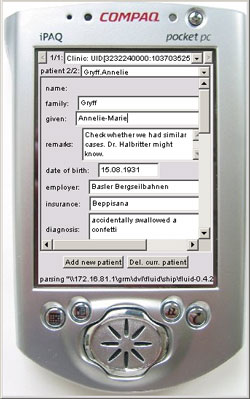
| A Fluid Computing application is no longer tied to a particular device. It may run simultaneously on several devices which the Fluid middleware coordinates, for example a small mobile PDA (left) and a big stationary PC display (right). When wireless network connectivity is available synchronization occurs keystroke-by-keystroke, otherwise updates are queued until connectivity is regained. |
The Fluid Computing middleware is a lightweight Java library that runs on PDAs such as Sharp ZaurusTM or PocketPCTM devices. The data structure of the replicated data is that of an XML document (other data structures are supported by the middleware as plugins). The API used by applications to manipulate that data structure is the Document Object Model (DOM) API of the W3C. Application developers interact only with the XML data structure and are shielded from the complexities of the replication mechanism.
A Sample Scenario
Imagine yourself to be a doctor at a renowned Zurich Clinic on the shores of the Lake of Zurich, where the rich and famous regain their health. All doctors and nurses are equipped with Personal Digital Assistants (PDAs) that give them access to their patients' data wherever they are. A wireless LAN provides connectivity to the PDAs throughout the clinic's premises.
You are walking along an aisle while reading the data record of Annelie Gryff on your Compaq iPAQ *. You have to decide on her exercise program. First you prescribe some swimming. Because the display is small you soon find yourself scrolling back and forth. You need a larger screen! You walk to a PC. Gryff's record appears on the PC, including the swimming exercises you have already entered. You continue listing prescriptions using the PC. Every keystroke is immediately reflected on your PDA. In an emergency you could immediately leave the PC - it would not be necessary to press a 'sync button' to synchronise the two devices.
For lunch you decide to go to Hiltl's restaurant, a vegetarian restaurant near Bahnhofstrasse. Obviously there is no longer a wireless connection to the clinic's intranet, but you still have Gryff's patient record on your PDA. You decide to prescribe a vegetarian diet - maybe that will do some good for her weight. As soon as you return to the premises of the clinic, this prescription propagates to the central patient database.
Link:
http://www.zurich.ibm.com/csc/mobile/
Please contact:
Marcel Graf, IBM Zurich Research Lab Switzerland
Tel: +41 1 724 8318
E-mail: grm@zurich.ibm.com
|


