| |
Content-based Retrieval Services in Peer-to-Peer Systems using Taxonomies
by Yannis Tzitzikas and Carlo Meghini
We investigate an approach where the participants of a peer-to-peer system use taxonomies to describe the contents of their objects and to formulate queries to each other. Inter-taxonomy mappings are employed in order to carry out the required translation tasks.
There is a growing research interest in peer-to-peer systems, like Napster, Gnutella, FreeNet and many others. A peer-to-peer (P2P) system is a distributed system in which participants rely on each other for certain services, rather than relying solely on dedicated and often centralized infrastructures. The membership in a P2P system is relatively unpredictable because it is ad-hoc and dynamic: services are provided by the peers that happen to be participating at any given time. Several examples of P2P systems have emerged recently, most of which are wide-area, large-scale systems that provide content sharing, storage services, or distributed 'grid' computation. Mainly they focus on specific applications (eg music file sharing) or on providing file-system-like capabilities. They do not yet provide content-based retrieval services: in most of the cases, the name of the object (eg the title of a music file) is the only way to describe the contents of the objects.
In general, the language that could be used to describe content and to formulate content-based queries is either free (eg natural language), or controlled, ie object descriptions and queries may have to conform to a specific vocabulary and syntax. The former case resembles distributed Information Retrieval (IR) systems and this approach is applicable when the objects of an application have a textual content. Our research focuses on the latter case where the objects of a peer are indexed according to a specific conceptual model which may be represented by various data models (eg relational, logic-based, etc), and content searches are formulated using a specific query language. Of course, a P2P system could impose a single conceptual model on all participants to enforce uniform, global access, but this would be too restrictive. Alternatively, a limited number of conceptual models could be allowed, so that traditional information mediation and integration techniques will likely apply (with the restriction that there is no central authority). The case of fully heterogeneous conceptual models makes uniform global access extremely challenging.
The first question to be investigated is which conceptual modelling approach is appropriate for P2P systems. We need an approach which makes it possible to bridge various kinds of heterogeneity in a systematic and easy manner. As there are no central servers, or mediators, the participating sources must have (or be able to create) articulations, ie, mappings, between their conceptual models in order to be able to translate exchanged queries appropriately. Such mappings could be constructed manually but the more appropriate - and more challenging - approach for a P2P network is automatic articulation. For all these reasons, a simple, clear, and application-independent conceptual modelling approach appears advantageous.
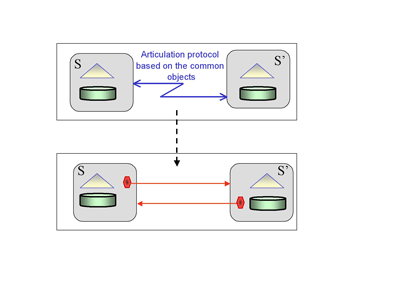
Our research investigates an approach that is based on taxonomies. Taxonomies are relatively easy to build in comparison with other kinds of conceptual models. They can be constructed from scratch or can be extracted from existing taxonomies (eg from the taxonomy of Yahoo!) using special-purpose languages and tools. Data-driven methods for taxonomy mapping can be automated and are therefore more appropriate for P2P networks. These methods can be used to create mappings between two taxonomies on the basis of the objects that are indexed by both taxonomies. According to our setting, a source in a P2P system can serve any or all of the following roles: primary source, mediator, and query initiator. As a primary source it provides original content to the system and is the authoritative source of that data. As a mediator it does not store any content: its role is to provide a uniform query interface to other sources. As a query initiator it acts as client in the system and poses new queries. Figure 1 shows the architecture of a network consisting of four peers A, B, C and D; two primary sources (C and D), one mediator (B) and one source that is both primary and mediator (A).
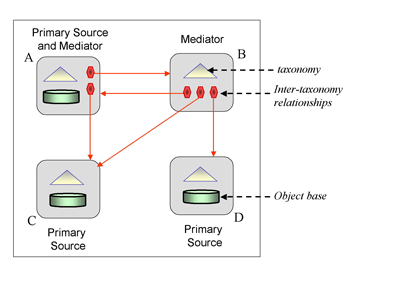 |
| Figure 1: The architecture of a P2P system using taxonomies and inter-taxonomy relationships. |
 |
|
Figure 2: Data-driven automatic articulation.
|
Apart from the classical problems that are currently being studied in the area of P2P networks with respect to query evaluation, such as object placement, replication, caching and freshness, the support of content-based retrieval services raises new questions. For instance, query forwarding requires techniques for query translation. Although this can be done using the techniques employed by mediators, the fact that in P2P systems we can have mutually articulated mediators means that endless-query-loops may arise and cause dead-lock phenomena. We are now studying techniques in order to avoid such phenomena and to optimize query evaluation.
The first author currently holds an ERCIM fellowship. This work is result of research conducted at ISTI-CNR, Pisa.
Please contact:
Yannis Tzitzikas - ISTI-CNR
Tel: +39 050 3152901
E-mail: tzitzik@iei.pi.cnr.it
|


