ERCIM News No.45 - April 2001 [contents]
ERCIM News No.45 - April 2001 [contents]
The CLRC Data Portal
by John Ashby, Juan Bicarregui, David Boyd, Kerstin Kleese-van Dam, Simon Lambert, Brian Matthews and Kevin O'Neill
A web-based data portal is currently under construction and based on a new metadata model of scientific data, for exploring and accessing the content of the data resources held within CLRC's main laboratories. This system comprises a web-based user interface incorporating access control and a metadata catalogue which interfaces to distributed heterogeneous data resources.
CLRC operates several large scale scientific facilities for the UK research community including accelerators, lasers, telescopes, satellites and supercomputers which all create copious quantities of data. These data resources are stored in many file systems and databases physically distributed throughout the organisation with, at present, no common way of accessing or searching them to find what data is available. It is often necessary to open and read the actual data files to find out what information they contain. There is little consistency in the information which is recorded for each dataset held and sometimes this information may not even be available on-line, only in experimenters' log books. This situation could potentially lead to serious under-utilisation of these data resources or to the wasteful re-generation of data. It could also hinder the development of cross-discipline research as this requires good facilities for locating and combining relevant data across traditional disciplinary boundaries.
To address these problems, a web-based data portal is being developed with the aim of offering a single method of browsing and searching the contents of all the CLRC data resources through use of a central catalogue holding metadata about all of these resources. The structure and contents of this catalogue are based on a metadata model for representing scientific data which is being developed by the project. Extensive use is being made of XML and related W3C standards for representing, transferring and manipulating the metadata.
The objective of this demonstrator project is to prototype these ideas by developing a pilot implementation of the proposed system which will enable researchers to access and search metadata about data resources held at the ISIS and SRS accelerator facilities in CLRC.
System Architecture
The system being developed has 3 main components:
- a web-based user interface
- a metadata catalogue
- data resource interfaces.
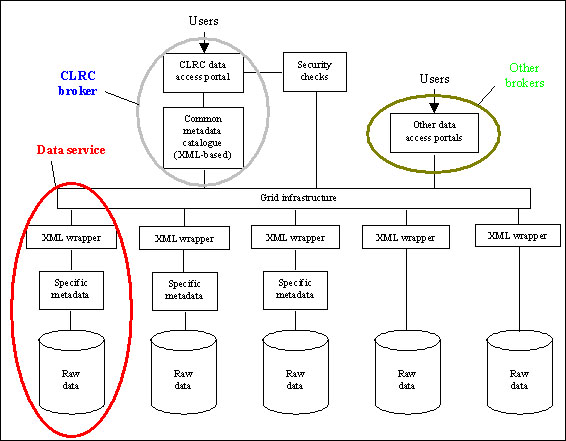
Architecture of the Data Portal system. In the pilot system these are integrated using standard Web protocols. Eventually it is anticipated that the system will exploit the emerging Grid infrastructure to offer a distributed interface to scientific data resources both inside and outside CLRC. The figure shows the architecture of the Data Portal system.
User Requirement Capture
To help us understand and capture the requirements of potential users of the data portal, we interviewed several experimental scientists, instrument scientists and data resource providers at each facility and also some external users. Based on their input, we constructed a series of user scenarios. These scenarios have been validated with those we interviewed and, based on them, we are developing use cases which are being used to design the user interface dialogue and to determine the required functionality of the database system underlying the metadata catalogue.User Interface
The user interface client for the data portal is being implemented using a standard web browser which will accept XML. At each step in the user dialogue, users are presented with a page generated from the metadata available at that stage of their search. They are prompted to refine or broaden their enquiry. User responses are interpreted by a user interface server process and converted into queries which are sent to a database holding the metadata. The results of each query are generated by the database as XML which is sent to the server process, parsed, converted into a displayable page using an XSL script and presented to the user.Metadata Catalogue
The logical structure of the metadata in the catalogue is based on the scientific metadata model being developed in the project. This model exploits our experience gained in developing metadata models for other domains. It is defined in XML using a DTD schema. The metadata catalogue is implemented using a relational database with a schema derived from the metadata model schema. This offers views of the data supporting the expected user enquiry patterns. Once the specific datasets required by the user have been identified using the available metadata, the catalogue will provide links to the files holding the actual data. Users can then use these links to access the data with their own applications for analysis as required.Data Resource Interfaces
The data resources accessible through the data portal system may be located on any one of a number of data servers throughout the organisation. Interfaces between these existing data resources and the metadata catalogue are being implemented as wrappers which will present the relevant metadata about each resource to the catalogue so it appears to the user to be part of the central catalogue. These wrappers will be implemented as XML encodings of the specific metadata relating to that resource using the metadata model schema.Project Status and Future Plans
This pilot project is planned to complete at the end of March 2001 with the operation of a working prototype data portal system. At the time of writing, the metadata model has been developed and validated, the user scenarios have been defined and the user interface, metadata catalogue and data resource wrappers are under development. The longer term goal of this work is to extend the data portal system to provide a common user interface to metadata for all the scientific data resources held in CLRC. We also envisage it being useful for locating and accessing data held in other laboratories. Where catalogues already exist in specific areas, we will not attempt to duplicate these but instead we will provide the user with a smooth connection into these domain-specific systems. It is anticipated that the resulting system will have wide applicability across many scientific disciplines. We are keen to develop its potential in partnership with others, particularly within a European context.Link:
CLRC e-Science web site: http://www.e-science.clrc.ac.uk/Please contact:
David Boyd - CLRC
Tel: +44 1235 446167
E-mail: d.r.s.boyd@rl.ac.uk