

by Joachim Hertzberg and Frank Schönherr
A robot control system is a special piece of software. It must cope with data in many different grades of granularity, from sensor readings to user-supplied mission data; it must yield purposeful action on different time scales, from collision reflexes to optimal long-term mission organization. Accordingly, a robot control program needs a special structure and organization that integrate these incoherent pieces into coherent overall action—it needs a special architecture. The Robot Control Architectures (ARC) team investigates robot control architectures that amalgamate reactive components working in close sensor-motor coupling, on the one hand, and deliberative, plan-based components working on an explicit symbol level, on the other hand. DD&P is one such architecture currently under development.
The reactive and the deliberative, plan-based aspects of robot control cannot a priori be ordered by importance or precedence: On a short term, reaction is first in order to avoid bumping into walls or falling down staircases; on a longer term, deliberated action is first in order to care about fulfilling the mission goals. Modern robot control architectures are hybrid, i.e., they contain different layers for reactive and for deliberative control components. Typically, a middle layer (often called sequencing layer) mediates between the reactive and the deliberative components, resulting in a three-layer architecture.
Dual Dynamics:
A Robot Control Framework
DD&P is a hybrid, two-layer robot control architecture. Its reactive layer is formulated in terms of Dual Dynamics (DD), a framework for specifying a set of robot behaviors as a continuous dynamical system, expressed as ordinary differential equations. It has been developed prior to our work. DD helps design and debug complex behavior systems that permit fast reactions to highly dynamical environments. Running DD applications include controllers for RoboCup players both within GMD (the mid-size league team of AiS.BE, see the paper by Bredenfeld in this issue) and outside GMD (the small-size league team of Free University of Berlin, which scored vice-champion in the IJCAI-99 world championship).
As is typical for behavior-based approaches, behavior sequencing can only be expressed somewhat clumsily in DD, and goals can be given to the robot only in form of a behavior program, which makes them difficult to change and communicate. Symbolic AI action planning approaches can do both much more elegantly, but they have difficulties expressing real physical action, at which behavior-based approaches are good. Combining the best of both worlds is mandatory, as all existing multi-layer robot control architectures attempt to do.
DD&P:
Coupling DD and Plan Deliberation
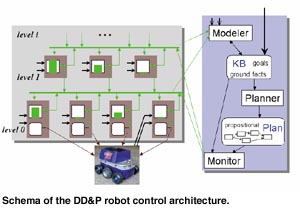
DD&P allows DD robot controllers to be coupled with a deliberative layer in a principled way, thereby designing a robot control architecture from existing and well-understood approaches both on the behavior and the planning side. DD is attractive to that end for the separation that it makes in every behavior between specifying physical action that the behavior proposes – the target dynamics for low-level behaviors, in DD terms – and a scalar value for its ‘subjective’ convincedness how appropriate its own contribution would be at the moment, the activation dynamics. The sketch of the DD&P structure in the figure has the DD part in the large grey box on the left, with single behaviors represented as brown boxes. Activation values of single behaviors and the flow of these values, respectively, are represented by green bars and arrows, respectively. Input from the robot sensors is shown by black arrows with open heads.
In its planning part (cf. the blue box at the right of the figure), DD&P proposes to use classical propositional action planning as the Planner component; we use existing modern, fast propositional systems like the planning graph planner IPP (Freiburg University). The idea is to make a quite abstract, typically short propositional Plan very quickly, make it available to the Monitor component, and start making the next plan or updating the current one immediately, thereby essentially planning all the time and overwriting plans as soon as new information becomes available. The hypothesis is that this throw-away-plan approach is practically superior to generating and using more expressive plans that take uncertainties into account, yet take much longer to be generated and suffer from problems of eliciting the required information about event and outcome probabilities in the first place; on the other hand, the approach promises to preserve the advantage of using plans for sequencing behavior and for projecting longer-term consequences of immediate actions.
As soon as the Monitor component finishes (with or without success) executing a Plan, it will pick as its next one the most recent one as generated by the Planner as current, and starts executing it as indicated by the Plan’s action order. Execution of an action in the current Plan is finished if its specified postconditions hold in the knowledge base (see below) or if some timeout condition is true. Executing an action means exactly to push up the activation values of behaviors that work in favor of that Plan operator, and to dampen the activation values of all behaviors counteracting that operator. In consequence, the Plan under execution does not determine the physical action of the robot; it rather biases the action towards that end. This philosophy is appropriate for a robot control that is supposed to be both reactive to unforseen changes in the world, and goal-directed in its long-term tactical or strategic behavior.
Information about current facts and goals gets into the propositional knowledge base by input from the user (the arrow entering there from top) or from a Modeler component. In general, the information in the knowledge base cannot be assumed to be timely and consistent, due to possible changes in the environment and to incomplete and inaccurate sensor information. The Planner must be able to work in the presence of such inconsistencies, and the Monitor must be able to recover from invalid plans or plan steps. In addition to sensor information and to the recent state of the knowledge base, the Modeler has access to the time series of the activation values of all DD behaviors. This data represents particularly aggregated sensor readings, namely, the world as percieved through the eyes of the behaviors, which allows certain action-relevant fact changes in the environment to be derived quite directly. In consequence, the DD part influences the plan part, or rather, the knowledge base, by providing via its activation values recent information about the environment and, in particular, about behavior alternatives in it. Of course, the regular sensor output and information from other agents or users, if available, are also used for knowledge base update.
All components within the plan part work in logical concurrence, as do the DD part and the plan part and all DD behaviors among each other. This logical concurrency is exploited in a physically concurrent implementation of the DD&P architecture that is currently under development.
Summary and State of Work
DD&P is a hybrid robot control architecture featuring the following three points:
Current work on the DD&P architecture builds on existing DD knowledge and DD programming tools as well as on a programming environment and methodology for concurrent programming (the Flip-Tick Architecture, FTA), all available within GMD’s institute for Autonomous intelligent Systems (GMD.AiS). We are currently implementing a prototype of a DD&P system in terms of FTA, aiming at a demo version of a controller of a KURT-II robot platform, as depicted in the photo in Fig.1.
Acknowledgements
Our work builds in its theoretical and practical aspects upon that of colleagues in GMD.AiS, most notably on DD and FTA. The respective co-operation is gratefully acknowledged.
Links:
http://ais.gmd.de/ARC/
Please contact:
Joachim Hertzberg – GMD
Tel: +49 2241 14 2674
E-mail: joachim.hertzberg@gmd.de