Dutch Language still Difficult for Automatic Translation
by Henk Nieland
English is a relatively easy language to automate. However, several other languages, including Dutch and Latin, contain features which make this far more difficult. At CWI a way has been found how to deal with some of these difficulties by applying techniques used in mathematically defined languages to the description of natural languages. The research is part of a project in which the cross-fertilization of linguistics and computer science is exploited.
"Vot flites aagh zair fghom Boston to Lozz Endzjelease tomogho eefning?" CWI researcher Annius Groenink asked this question to a large SUN workstation while visiting a colleague in Cambridge some time ago. On the workstation ran a program that could translate spoken sentences related to flight reservations into French. Ten seconds later it sounded in good French: "Quels vols y a't-il de Boston a Los Angeles demain soir?" The same sentence pronounced with a lot of ... euh ... 's in it and with an even stronger Dutch-French accent did not lead the computer astray. The colleague explained that only a real Frenchman can speak with such an accent that the computer will go mad ... .
The example indicates how well translation jobs like this are handled nowadays. For specific programmes with a restricted vocabulary, like flight reservations, this is far better than is usually thought. However, automatic translation still shows some substantial gaps that have not always sufficiently drawn the technicians' attention. One of the reasons is their concentration on English, which in a mysterious way is more related to computer languages than Dutch. The difficulties in Dutch (for example the word order) present themselves even stronger in Latin: "For the computer Latin is an extreme form of Dutch", says Groenink.
Groenink first studied the necessary changes in existing description techniques for natural languages in order to deal with more "complex" languages like Dutch. To fit a language for automation its grammar should be described with such precision that on this basis a computer can automatically parse sentences. Such descriptions are being made nowadays with some regularity for English and French, with satisfactory results.
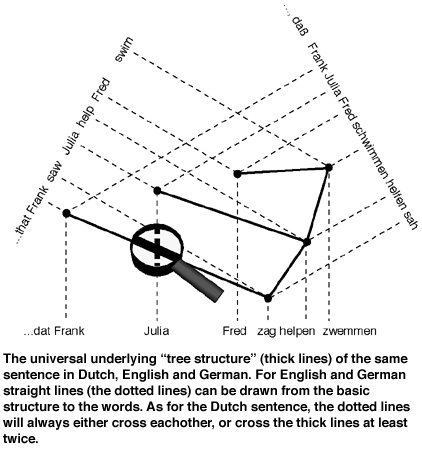
However, existing methods turn out to have a rather poor performance when applied to Dutch. One cause lies in the difficulties with the construction of an underlying "tree structure" in Dutch. Contrary to English and computer languages, many Dutch sentences do not have such a tree structure (see Figure) - a well-known and old problem in linguistics.
The solution proposed by Groenink was known already for some time among formal language theory researchers (strangely enough outside The Netherlands), but was never applied in this context. A part of a sentence, which corresponds to a branching point in the tree, is viewed not as just one string of words within the sentence, but as two or more separate parts. Such extensions of the existing methods provide in principle a description of Dutch which can serve as a basis for automation. The proposed method turns out to work also for a language like Latin, in which - according to common opinion - the word order is completely free. Groenink formally showed that this order is not at all as free as was assumed, thus giving latinists who doubted this already, an argument to reinforce their ideas about the role of word order in various kinds of Latin texts.
Word order also afflicts German, as can be seen in a translation program of dictionary producer Langenscheidt (on the Web: http://www.gmsmuc.de/ trans.html). Simple German sentences are translated fairly well into English or Spanish, but already a slight increase in complexity causes the program to produce a totally wrong word order, and a sentence like "Sah ich dich dem Mann gestern schwimmen helfen?" is not understood at all.
To come up with a theoretical solution is one thing, to show that it also works in practice is quite another story. Groenink paid particular attention to the links between these two aspects of his research and proved that his proposed extensions with regard to parsing do not cause an exponential growth in computing time. In addition, Groenink could make plausible that more realistic implementations of his software, where for example checks on cases and singular/plural are included, also remain efficient. For more information, see Annius Groenink's home page at http://www.cwi.nl/~avg/
Please contact:
Annius Groenink - CWI
Tel: +31 20 592 4113
E-mail: Annius.Groenink@cwi.nl