

by Niclas Ohlsson, Kristian Sandahl and Bo Bergman
It is a well-known fact that software in general has a relatively low level of reliability, as noted, for example, in the IEEE Software Journal July 1993 or, for a popular scientific presentation, Scientific American, September 1994. Compared with hardware, it is difficult to measure the reliability that can in fact be achieved. This leads to a lack of certainty with regard to costs, which in turn may result, for instance, in a decision not to develop software despite the fact that the need is there and the techniques are available. With this in mind our aim is to measure statistically, ensure and predict the reliability of both the software product as such, as well as the process involved in creating the software. With this in mind our aim is to measure statistically, ensure and predict the reliability of both the software product as such, as well as the process involved in creating the software.
Statistical Usage Testing
During the past few years Statistical Usage Testing (SUT) has attracted attention within the software industry sector. In principle SUT involves generating the test cases used in the functional testing of the software from an operational profile which reflects as closely as possible the actual circumstances the program is to be run in. In concrete terms the operational profile can be described as a probabilistic model of various possible inputs. For practical purposes these inputs are divided into a number of equivalence classes where each class is designated a certain probability of occurrence. Collecting and analysing the data is the harder part of producing operational profiles and there are no recognized standards or systematic methods to support them. Consequently we consider important to carry out such an analysis; performing a Bayesian analysis is a possible candidate, as acquiring sufficient data is a general problem.
The subsequent reliability analysis is performed with two aims in mind:
In summary we expect that SUT will provide more dependable and cheaper reliability judgements. Furthermore we expect that as a side effect it will have positive consequences on the process of producing software as a result of a better understanding of how the program is used, which is gained by building a probabilistic model.
Process improvement.
To create a basis for improvements in the software process we are currently building a model which includes a description of when in the process a product fault is introduced, detected and corrected. Six larger projects within the Ericsson sphere of activities are being used to gather data using the FIDAC fault classification method. FIDAC is an extension of an existing fault classification method for the test phase, to manage faults that are detected in earlier phases, such as inspection of the design document. Each fault that is found during the process is classified according to where the fault was discovered, introduced, the technical type of the fault, its consequences and why it arose. From these data we expect to be able to build a statistically-based model which serves as a basic level from which we can assess technical improvements and which also highlights main weaknesses in the process where further research can be expected to be of most use.
In parallel to this process modeling we are also developing strategies for predicting which parts of the software faults are most likely to arise in. Knowing this enables both the identification of factors contributing to the cause of the fault and also planning resources such as assigning the most experienced staff to the modules most likely to cause trouble. The first stage of this work was to develop a new metric for flow diagrams from a previous design phase. In an experiment, the method based on a combination of complexity and size, was able to identify 15% of the modules in a large system which accounted for 68% of the errors discovered during function testing. A tool called ERIMET was developed to automatically support extensive validation and which simultaneously aims to:
By virtue of access to such extensive realistic data the project is unique in software research and a report will be provided in Niclas Ohlsson's licentiate thesis in Spring, 1996.
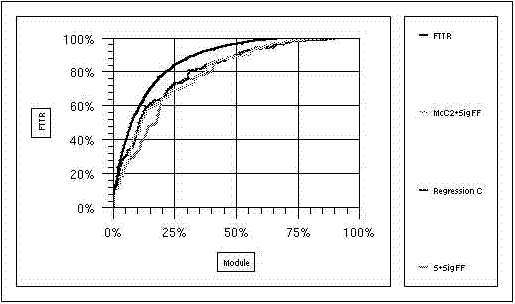 Figure : Predicting modules where faults are likely to occur. The upper curve shows the accumulated number of Function Test Trouble Reports (FTTR) as a function of the number of models. The diagram technique employed shows the modules ordered in a falling number of FTTRs. The lower curves show three different metrics based on measuring more than 130 modules in the design phase. Regression C involves a large number of variables with the risk that the metric is tailored to the particular data. The two other metrics combine a measure of the topological complexity (McC2) and size (S) with the number of new or modified signals used in communication with the modules (SigFF).
Figure : Predicting modules where faults are likely to occur. The upper curve shows the accumulated number of Function Test Trouble Reports (FTTR) as a function of the number of models. The diagram technique employed shows the modules ordered in a falling number of FTTRs. The lower curves show three different metrics based on measuring more than 130 modules in the design phase. Regression C involves a large number of variables with the risk that the metric is tailored to the particular data. The two other metrics combine a measure of the topological complexity (McC2) and size (S) with the number of new or modified signals used in communication with the modules (SigFF).