

by Andrea Bozzi and Antonio Sapuppo
The close relationship between the preservation and the consultation of ancient documents has led the Commission of the European Union to encourage different organizations, such as libraries, research institutes and industrial enterprises, to carry out concrete interventions. In this context, an innovative project proposed by ILC-CNR for the preservation of old manuscripts using digital optical tools and the creation of a specialized workstation for the transcription and electronic processing of such documents is now under way as part of the CEU programme for "Telematics Systems in Areas of General Interest (Libraries)".
The Institute for Computational Linguistics, Pisa, is developing a system which should provide philologists, papyrologists, epigraphists and other scholars working with ancient texts, frequently damaged and/or difficult to read, with a system which makes it easy to:
Text-Image Correspondence
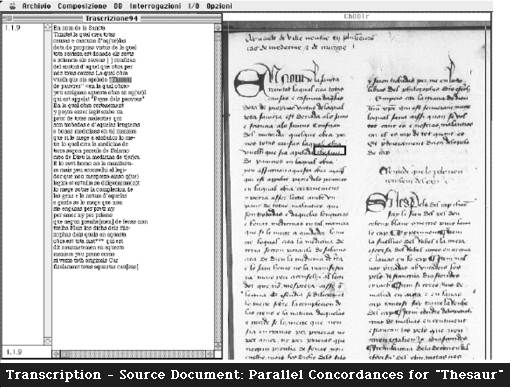
The original document, or a photograph or microfilm version of it, is optically scanned. The digitized image is then displayed on the screen with a very high definition to ensure legibility even after considerable enlargement. A second window contains the scholar's transcription of the document. New text is entered or already transcribed text can be viewed and corrected in this window.
The numerical representation of the image is processed in order to distinguish the written parts of the document from the background. Separate columns of text are recognized automatically. Digital image intervention consists in the identification of particular features which enable the machine to distinguish the areas with printed text from the rest. It must be remembered that we are dealing with very old texts which are frequently damaged or present irregular markings. The exact zones of text are recognized by analyzing a histogram showing the distribution of the chiaroscuro values. Scanning the image vertically, the points in which the program identifies a clear-cut separation between black and white tonalities are considered as column divisions and marked with line(s) appearing on the screen; the correct disposition of these lines can be checked. This method is also used for automatic identification of lines of text. In this case, the program works horizontally, analyzing the histogram to recognize and separate the chiaroscuro values. The program counts and numbers the lines progressively.
When the text has been transcribed, a final processing of the image will match each word in the transcribed text with the portion of the source document in which it appears. The system first examines the chiaroscuro values pertinent to each line in order to identify divisions between words; it then compares the word zones identified in the image electronically with the transcription in which the exact number of words for each line is computed. Any changes made in the transcription of the text are automatically transferred to the image of the source document without any intervention by the operator. Second thoughts regarding word division or a different interpretation of the text will thus produce a different word-image link. The transcribed text and the segmented image are displayed in two separate windows on the screen and the operator can check and correct any mistakes.
When the transcription has been checked, the current segmentation and links between transcribed and source documents are recorded and queries can be made:
Restoration
We are now working on providing our system with an intelligent component that can perform restoration operations. We are adopting the following strategy. A special tool will identify clearly legible characters in the digitized image; for each character, the system will produce a model represented by several relations obtained calculating the size of each line, stroke and curve and including certain stylistic variations. A specific character on the keyboard is then attributed to each model representation. Portions of unclear characters are successively submitted to the system which suggests a possible integration. For each hypothesis, the processor will show the graphic representation (and corresponding alphabetical value) having the highest number of features in common with the fragment. Other models and therefore other interpretations of the text are proposed in decreasing order of probability. The same procedure is used for the entire set of characters of the text. The program compares previously obtained models with the current fragment; the result of this comparison corresponds to the proposal of integration. Several connected CPUs and neural networks are being used to process the large volume of data involved.
The system performance can be improved by the addition of a textual/linguistic component: the text of the fragment including both the restored and the easily legible parts is compared with an textual archive where there is a good chance of finding the piece being examined. In other cases, when the fragment presents many different possible interpretations, the data contained in the list of forms extracted from the textual archive and subjected to a number of statistical operations (e.g. production of digrams and trigrams) can be used as a filter. For each hypothesis formulated by the graphic component for a sequence of characters a statistical-linguistic assessment is performed; the list of all words containing these elements in initial, central or final position is extracted from the general index and the most appropriate can be chosen.
{kind=link}