

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by Stephane Marchand-Maillet, Eric Bruno and Nicolas Moënne-Loccoz
Multimedia management is a challenge common to several user groups, from individual users to corporate groups. It is therefore of high importance to define a platform that will resolve the contradictory issues of simplified description tasks and enhanced querying capabilities. We show that, based on technology common to Digital Libraries and the Semantic Web, we can propose such a framework.
The description of visual documents is a fundamental aspect of an efficient multimedia information management system. This is supported by the fact that a significant part of the information contained in the document can only be captured via the explicit description of a human operator. However, creating such a description is known to be both expensive and incomplete by nature. The importance of context may lead to ambiguous or even contradictory content descriptions. It is therefore critical that visual content description is done in the most favourable environment.
In the context of multimedia retrieval, MPEG-7 seems to be a good candidate as a description schema, since it caters for manual and automated description processes. However, MPEG-7 description tools are still largely not operational. Further, although based on XML, MPEG-7 hardly unifies with other schemes proposed along the Semantic Web route. Rather than pursuing the MPEG-7 direction therefore, we have constructed a generic ontology-based annotation framework, in close relationship with the emerging W3C standards RDF (Resource Description Framework) and OWL Web Ontology Language. These developments are therefore aligned with the Semantic Web initiative, which shows that rich semantic annotations are needed for automating truly useful processes, including multilingual support.
Structured Description Model
The base of our framework is DEVA, a description scheme that has many favourable properties. DEVA acknowledges the power and utility of both the Dublin Core (DC), largely used in the Digital Libraries community, and the combination of RDF and OWL as description framework and knowledge management framework respectively, both arising in the frame of the Semantic Web.
The latest version of the Dublin Core vocabulary is composed of fifteen properties, among which we can find dc:title, dc:creator, dc:format or dc:subject. DEVA uses and extends these properties within the deva:Document wrapper class, and preserves their semantics. Being a Dublin Core extension allows the DEVA model to take advantage of a recognized standard, making it compatible with most of the software tools already available.
Wrapping DC elements has also been done in W3C's RDFPic tool using the PhotoRDF, where the subject property is constrained by a content schema. By contrast, in the DEVA model the subject property is associated with the Subject class. This class allows the semantic content of a visual document to be described. The specification of the content description is an OWL ontology designed according to the four expressive levels seen earlier:
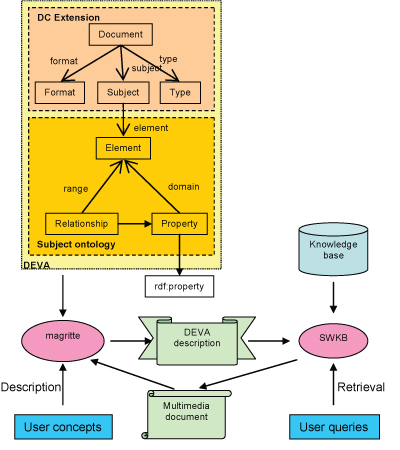 |
| Figure 1: Architecture of the proposed structured document management system. |
Interaction Principle
An annotation tool prototype, called magritte, has been implemented to evaluate our DEVA model and to validate its relevance in the frame of image annotation. The prototype is written in Java and makes use of the open-source Jena Semantic Web Framework developed by HP Laboratories. The interaction is simplified in many ways. The action of describing a multimedia document is almost reduced to the baseline classical keywording operation. However, the tool fully exploits the context in which keyword input takes place. Hence, every action is aligned against the knowledge base. Also, the definition of properties related to enumerable content is controlled by restricted choices. In this way, the document description is incrementally constructed by narrowing the scope of possible entries.
Interaction Principle
A structured focused description is useful only when related to corresponding queries. However, in the context of an economical description, queries should, in principle, target known properties. For example, a picture whose subject is said to be a 'bird' would never respond to a query related to 'animal' in a direct search system. In fact, a 'bird' would be as close as a 'car' from such a query. The solution to this is clearly to make use of an external knowledge base to extend the 'bird' concept to that of an "animal".
This is the aim of the Semantic Web Knowledge Base (SWKB) that we have created to complement our description framework with a reasoning engine capable of processing high-level queries. SWKB is an abstract framework embedding a reasoning engine to process DEVA (RDF) data against a classical OWL-based knowledge base using RDF/S semantics. By default, SWKB embeds the Jess (Java Expert System Shell) as a reasoning engine and may well be extended to other types of reasoning.
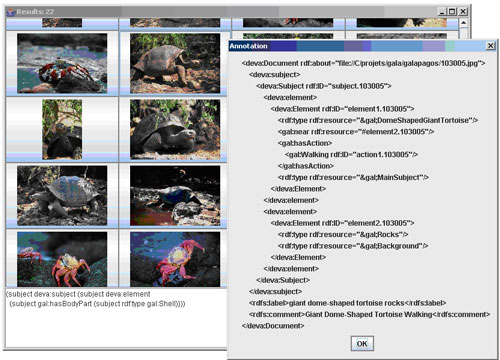 |
| Figure 2: The SWKB demo tool illustrating the query "something with a shell". |
Extension
Thus, the above framework makes it possible to create multimedia descriptions aligned with typical assets found in digital libraries, while opening up the possibility of extended queries. We are currently extending it in directions related to content-based analysis of multimedia documents with auto-annotation as a bootstrap procedure, and the use of retrieval to organize the description at the collection level. This extension will partly take place in the domain of the Cultural Heritage asset management via the MultiMATCH project (http://www. multimatch.eu).
The support of the Swiss National Science Foundation is gratefully acknowledged.
Link:
Viper Group on Multimedia Information Management: http://viper.unige.ch
Please contact:
Stéphane Marchand-Maillet, University of Geneva, Switzerland
Tel: +4122 379 7631 / +41 22 379 7660
E-mail: marchand![]() cui.unige.ch
cui.unige.ch
