

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by John M Lervik and Svein Arne Brygfjeld
Digital libraries are experiencing rapid growth with respect to both the amount and richness of available digital content. This is the result of a range of large-scale digitization projects on books and periodicals that are occurring locally, nationally and internationally. Furthermore, a number of libraries are digitizing other information carriers such as still images, audio and video. Much of the information in libraries has good metadata; to supplement this, OCR technology is used to extract text-based information from textual information within digitized images.
As a consequence of the huge amounts of digital content becoming available, modern search engines are now being introduced in digital libraries. Online users are accustomed to Internet search engines: they expect simplicity, speed and cross-collection searching. Given the complexity and amount of digital content, third-generation search technology is required to provide highly relevant search capabilities. This search technology also scales in a cost–efficient manner and provides proven methodologies for the operation and maintenance of these systems. Hence, as digital libraries grow in content volume and diversity, this third-generation search technology provides a convenient platform to give users what they expect with respect to relevance, functionality, and speed.
The exponential growth in the volume and diversity of digital library content represents both challenges and opportunities. One obvious challenge is to keep the query response time low. While conventional search technology gives acceptable query response times when searching is limited to metadata only, it cannot handle the addition of large amounts of OCR text. With a third-generation platform, searching can be performed across multiple systems and on all the available content.
Another significant challenge is to provide the most relevant information to the user. This involves finding and ranking hits from large amounts of information, as well as retrieving relevant information that the user does not know exists or that she/he may not even know how to search for. The most relevant information may exist in another database and be described in ways that do not show up in traditional searches. Cross-database searching is another area where traditional systems are insufficient. Some systems provide distributed searching through the use of Z39.50, OpenURL and other protocols. However, they are very slow due to protocols and long response times in source systems, and do not provide one consistent relevancy function across all of the content sources.
A third challenge is searching a rich set of information types, such as the content of still images or audio. With such a diversity of information, there is a clear need for a more dynamic inclusion of new search methods on various information types.
Third-generation search engine technology is designed to combine the scalability of Internet search engines with new and improved relevance models. This will include contextual relevance, allowing searches to be performed across any type of content and any type and number of sources. Libraries already have a wealth of experience in harvesting information to build centralized repositories of both metadata and content. Such environments are well suited for exploiting the capabilities of search engine technology and thus meeting the challenges above. The National Library of Norway has recently implemented infrastructure based on these principles, with the FAST search platform as a core component. This is shown in Figure 1.
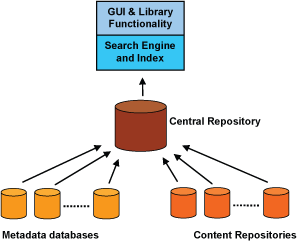 |
| Figure 1: Functional model at the National Library of Norway |
This model makes it possible to perform very fast and relevant searches of large amounts of information residing in disparate databases. In this case, more than thirty metadata sources are included in addition to content from digitized newspapers, books and journals. The search service provides access to the complete palette of information at the library, including books, periodicals, still images, audio and video. It also serves as a base for statistical purposes, as well as management information.
A major advance in third-generation search technology is the introduction of contextual searching. The current Web search approach provides links to documents based on a hard-wired ranking method, such as the number of inbound links or scientific citations. This approach has some fundamental limitations for use by digital libraries. First, researchers cannot find what they don't know exists, so all queries must be specified by the user and there are no tools to crate data-driven content analysis. Second, researchers will only get access to the 'most popular' or 'newest' articles as defined by a black-box relevance function. It is possible that neither of these forms of ranking will illustrate the results or trends the researcher is interested in. Third, the user interaction does not provide any learning for the researcher. The researcher must open and read the full articles in order to assess them, and this time investment is usually significant. Hence, the overall approach offered by most library services does not make the best use of the offered content.
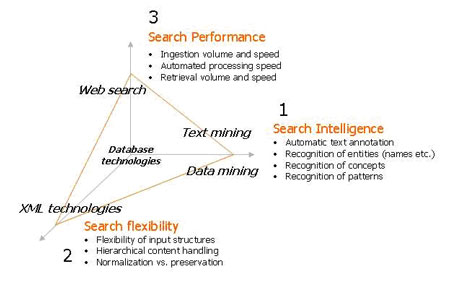 |
| Figure 2: Contextual searching. |
Contextual searching has been designed to address these challenges. Figure 2 illustrates some of the key components in the foundation of a contextual search.
Contextual searches introduce new metaphors for user interaction: each document is further decomposed into semantic components that can be retrieved and analysed across billions of articles. Even ambiguous, open-ended queries can therefore be answered with highly accurate 'table-of-contents'-type results relating to factual information contained inside the relevant documents. Hence, in addition to getting access to highly relevant search results, researchers can:
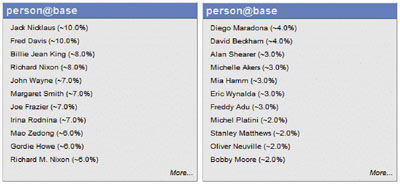 |
| Figure 3: Comparison of results from a standard Web search (left) and a contextual search (right). |
As an example of how contextual searching improves search precision, we have run two test queries against the online encyclopedia Wikipedia (see Figure 3). Results on the left are from the query "persons that appear in the same document as the word 'soccer'"; those on the right are from the query "persons that appear in the same context (ie paragraph) as the word 'soccer'". The improvement in result quality is striking, yet the first list of results corresponds to a standard Web search result which until recently was considered state-of-the-art!
Contextual searching allows the information provider to preserve all the original information and spend less time annotating and classifying the content. To end users, it gives ease-of-use through better content and features, and creative freedom to ask questions the providers may not have planned for. In essence, the value of information should not be judged by the ability to store it, but by the ability to use it.
In summary, contextual searching enables deep semantic analysis and refinement across structured, unstructured and rich media, and dynamic interpretation of contextual meaning of the content. The overall results of the contextual combination are vastly improved discovery, schema exploration and disambiguation capabilities. Contextual search is all about turning information buried inside digital libraries into value for researchers.
Please contact:
John M Lervik, CEO Fast Search & Transfer ASA (FAST), Norway
E-mail: John.Lervik![]() fast.no
fast.no
Svein Arne Brygfjeld, Digital Libraries,
The National Library of Norway
E-mail: svein.arne.brygfjeld![]() nb.no
nb.no
