

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by Arne Jacobs and Nektarios Moumoutzis
Although video search technology is making rapid strides forward, video search engines continue to be challenged by the semantic gap. This is the difficult problem of relating low-level features to the higher-level meaning that corresponds to the human-like understanding of video content, and a solution to it is necessary for effective retrieval performance. In the Delos Network of Excellence, specifically in task 3.9, "Automatic, context-of-capture based Categorization, Structure Detection, and Segmentation of News Telecasts", our approach to bridging this semantic gap is twofold. First, we restrict the application domain to news videos, and second, we exploit the combination of multimodal analysis with semantic analysis based on ontologies.
A key observation in bridging the semantic gap in the news video domain is that semantic concepts in news videos are conventionalized in many ways. This fact can be exploited. For example, segments in news telecasts do not appear in arbitrary order, but rather follow a relatively strict scheme that determines the order of segments. Different news stories are also usually separated by anchor shots containing the presentation of the story that follows. This telecast structure allows the viewer to easily recognize different segments. Each news format has its own structural model.
We assume that these news format models can be described with context-free grammars. Such a grammar can aid the segmentation process by removing ambiguities in classification, or by associating certain audiovisual cues with segment classes (eg news story, presentation). It models all interesting constraints in visual, audio and textual features, that are partly due to the way news programs are produced and partly to the habits and preferences of journalists and other agents related to the news production.
For parsing of a news video following a corresponding model, we propose a system consisting of two main types of interoperating units: the recognizer unit consisting of several modules, and a parser unit. The recognizer modules analyse the telecast and each one identifies hypothesized instances of 'events' in the audiovisual input. Such events can be higher-level concepts like a specific person appearing in a shot (eg the anchor), the appearance of a certain series of frames (eg the introduction sequence, with which many news broadcasts commence), or low-level concepts, eg the similarity of two frames.
The system contains three distinct recognizer modules: the audio recognizer, the visual recognizer and the semantic recognizer. The visual recognizer identifies video events in the news stream, such as a face appearing at an expected position in the video or the presence of a familiar frame according to the expected structure of the broadcast. The audio recognizer identifies audio events such as the presence of speech or music, the detection of predetermined keywords, and clustering of speakers. Finally, the semantic recognizer identifies the semantics involved in the telecast. This includes topic detection, high-level event detection, discourse cues and possible story segmentation points. The figure shows a sketch of the system architecture.
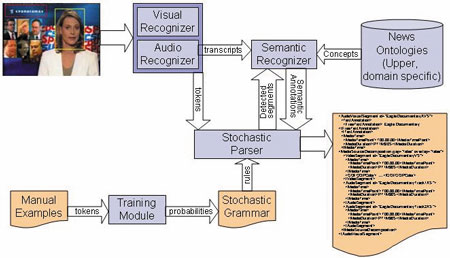 |
| The system architecture shows the interoperation between regognizers, grammar, and parser. |
The recognizers normally only communicate with the parser in a one-way communication, providing a sequence of predetermined event 'tokens'. However, in the case of the semantic recognizer there may be an exception, since that module requires a transcript of the telecast in order to perform its analysis. In the case where the transcript is not provided through the input (eg in the form of closed captions), the audio recognizer provides this information.
A stochastic parser using a probabilistic grammar analyses the identifications provided by the recognizers. In essence, the recognizers provide the parser with actual lexical tokens just as a lexical analyser would provide to a programming language parser. The grammar represents the possible structures of the news telecast, so the parser can identify the exact structure of this telecast. When the parsing is complete and all the structural elements of the input have been analysed, the semantic recognizer uses that information to identify story topics and events, and to assign all required semantics to the structure tree.
The grammar for each broadcast station, even for different news programs of the same station, is distinct. This is because the grammar captures the directing elements of the broadcast, and no two programs have exactly the same directional structure. Therefore, a grammar must be produced manually for each program examined.
To determine the probability values of the rules in the grammar, it is necessary to (currently manually) complete a training process, which uses a set of correctly labelled news recordings in the form of a sequence of tokens.
Finally, the semantic recognizer has access to an upper ontology, covering all necessary aspects required for multimedia content description, as well as domain-specific ontologies created for news. The concepts acquired from these ontologies will define those detectable semantics that can be identified in the telecast.
We are currently investigating methods for automatically determining the audiovisual cues that characterize a given news format, by analysing a set of example recordings of that format. Based on the experience that these audiovisual cues do not change frequently, we expect videos from the same format to have many nearly identical video and audio sequences at similar time-points. We are trying to exploit this by using an inter-video, intra-format similarity analysis. In the future, this will overcome the limitation of manual creation of format models.
Please contact:
Arne Jacobs, Universität Bremen, Germany
E-mail: jarne![]() tzi.de
tzi.de
George Ioannidis, Universität Bremen, Germany
E-mail: george.ioannidis![]() tzi.de
tzi.de
