

ERCIM News 66July 2006Special theme: European Digital Library Contents This issue in pdf Subscription Archive: Next issue: October 2006 Next Special theme:
|
by Periklis Georgiadis, Nicolas Spyratos, Vassilis Christophides and Carlo Meghini
Searching a Digital Library (DL) using traditional database (DB) or knowledge base (KB) query-answering techniques is constrained by the precision and completeness of answers: precision may lead to an empty answer, while completeness may result to a huge answer. Yet reformulating the query-filtering conditions to avoid one handicap may lead to the other: that is, relaxing the filtering conditions may lead to a huge answer, while strengthening the conditions may lead to an empty answer. Using preference-based queries to personalize user access to a Digital Library allows result sets to be tuned between these two extremes.
In general, a DL can be seen as a collection of documents residing in various information sources (on the Web). Each document can be naturally represented by a single row in the DL catalogue. A document's row contains its ID and description. The description involves a number of multi-valued attributes, called in the sequel DL columns. The values for each column (referred to as terms of that column), come from a specified sort associated with the column, and may be organized in a hierarchy (eg taxonomy of subject headings). A traditional DB or KB query over the DL catalogue filters its rows according to the Boolean conditions on columns as defined in the query, but offers limited support for ordering the documents in the query answer.
In order to personalize DL access we advocate an enriched form of queries, called preference-based queries. A preference over a column C of the DL catalogue is any reflexive and transitive binary relation ? (preorder) over the terms of C. In other words, each pair t -> t' of the relation denotes that t is preferred to t'. The presence of both t -> t' and t' -> t makes the terms t and t' equivalent, meaning that if a document described by t is not in the DL then one described by t' is an acceptable alternative (and vice versa).
A preference-based query comprises three parts:
Of these three parts only the term-filtering part q is always submitted online. The remaining two parts can either be submitted online (together with q), or taken from a stored user profile and appended to q automatically. In either case such an access to a DL is a personalized access.
As DL columns are in general multi-valued, and if we consider different power domain orders, a partial order preference relation over the terms of one column may define a partial preorder over the documents in many ways. The choice is application-dependent, but in general the Hoare and Smyth relations are good candidates, considering that they preserve the initial order properties.
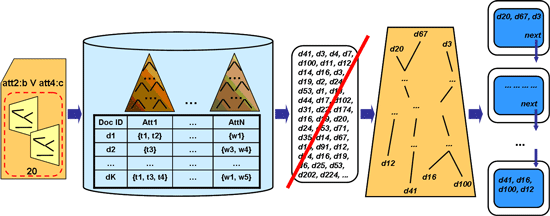 |
| A preference-based query over a Digital Library. |
The evaluation of a preference-based query begins by computing the set of documents ans(q) which satisfies the query part q. Then, for each preference relation over a DL column a partial order over the set ans(q) is induced. As a partially ordered set of documents is not convenient to return as a response to a user query, we can employ variants of topological sorting to induce an ordered partition of the set ans(q). This is a collection of mutually disjoint blocks of documents in a linear order that respects the partial order - and thus the initial user preferences. In this linear order each block would correspond to a screen of relevant documents that is shown to the user, with the most preferred documents appearing first. The parameter k is used as a stop condition to end the output process (when k documents have been shown to the user).
A user may express preferences over different DL columns and each preference incurs a different ordered partition. Combining preference relations over different columns and taking into account user prioritization over the columns boils down to defining a partial order over the Cartesian product of n partially ordered sets. This is a well-known problem for which various solutions exist, such as the lexicographic ordering or the Pareto orderings. In our case, we compute the product of all partitions and we use one of the known orderings on the topological distances of documents to generate the required final ordered partition.
The problem of preference-based queries for digital libraries is studied jointly by the Institute of Computer Science, FORTH, Greece; the Laboratory of Research in Informatics, LRI, France; and the Institute of Science and Technology in Informatics, CNR, Italy, within the framework of the DELOS European Network of Excellence in Digital Libraries. With respect to similar approaches, the main contribution of our work lies in the combination of ordered partitions coming from preferences expressed over multi-valued attributes, rather than over functional attributes describing traditional database tuples or objects. Our framework is expressive enough to produce sequences of documents from descriptions expressed in diverse data models (eg XML, RDF/S) with respect to a variety of user preferences, while also including priorities over the preferences.
Link:
http://www.ics.forth.gr/isl
Please contact:
Nicolas Spyratos, LRI, University of Paris South, France
Tel: +33 1 69156629
E-mail: spyratos![]() lri.fr
lri.fr
Vassilis Christophides, ICS-FORTH, Greece
Tel: +30 281 0391628
E-mail: christop![]() ics.forth.gr
ics.forth.gr
Carlo Meghini, ISTI-CNR, Italy
Tel: +39 050 3152893
E-mail: meghini![]() isti.cnr.it
isti.cnr.it
