Representation and Communication of Multimedia Data and Metadata
by Sara Colantonio, Maria Grazia Di Bono, Massimo Martinelli, Gabriele Pieri and Ovidio Salvetti
In recent years the increasing role of Multimedia (MM) data, in the form of still pictures, graphics, 3D models, audio, speech, video or their combination (eg MM presentations), in the real world, has lead to a demand for better procedures for the automatic generation and extraction of both low level and semantic features from multi-source data in order to enhance their potential for computational interpretation and processing.
MUSCLE (Multimedia Understanding through Semantics, Computation and Learning) is a European Network of Excellence (NoE) that aims fostering close collaboration between research groups in multimedia data mining and machine learning. Within MUSCLE, our research is focused on investigating standards and tools that allow interoperability of heterogeneous and distributed (meta)data also by enabling data descriptions of high semantic content (eg ontologies, MPEG-7 and XML schemata) and inference schemes that can reason about these at the appropriate levels.
Metadata are used to represent the value-added information that describes the technical and semantic characteristics associated with MM data. Metadata make data more processable, allowing more efficient retrieval or classification, quality estimation and prediction based on Machine Learning techniques in both single and multiple-modality.
Many initiatives for metadata standardisation have been proposed in order to describe multimedia content in various domains. Scientific and industrial communities tend to create their own standards tailored on their particular needs. This could cause an unrestricted growth in the number of available standards making the integration and sharing of MM data between different communities (vision, speech, text, …) very difficult. A recent approach is to combine a specific MM metadata standard with other standards that can be used to describe similar application domains, in order to provide a more comprehensive characterisation of heterogeneous MM data without creating a new standard.
From a recent survey of the state-of-the-art, we have identified two main approaches to MM data processing. On the one hand, people who employ MM data for scientific purposes use consolidated MM data processing algorithms, on the other hand, applications following a Content Based Query (CBQ) paradigm require content representation.
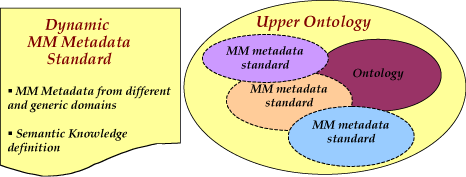
This scenario, which involves MPEG-7 or metadata models tailored on the specific requirements of a given community, highlights a possible limit for interoperability among different communities. We feel that two important issues must be considered in order to achieve an efficient and integrated use of MM metadata: (i) a common MM standard format able to describe and represent the intrinsic heterogeneous nature of MM data and their semantics must be defined; (ii) more abstract models (eg ontologies) and the related mapping tools are needed to “represent” and “translate” different metadata sets whose elements are correlated on the basis of the same or similar meanings so that MM applications can use ontology knowledge in addition to the metadata (see the figure).
In the first case, one strategy could be to use MPEG-7, which is currently the most mature MM metadata standard, due to its generality and extendibility. MPEG-7 permits an extensive description of multimedia content not only at the low-level feature level (visual, audio, multimedia) but also at the higher semantic level. However, its freedom in terms of structures and parameters is such that, in general, it is not easy to interpret MPEG-7 produced by others. To overcome this problem, a possible solution could be to build an MPEG-7 ontology.
In the second case, the introduction of a high-level ontology covering multiple domains could be convenient; this solution would have the advantage of being more independent of the lower metadata standards. However, the definition of a completely new ontology is a very complex task.
When constructing ontologies, standard tools like XML, RDF and OWL should be considered. XML supports the definition of constraints for structure, cardinality and data-types but does not support the definition of semantic knowledge. RDF provides mechanisms to describe MM resources, group them and represent their semantic relationships, but does not offer mechanisms to define general axioms, which can provide a stronger semantic representation. OWL can be used to derive logical semantic consequences but has expressivity limitations, which could be overcome by using specific rule languages (eg RuleML, SWRL, ORL, ...) extending OWL axioms with additive and more expressive rules.
The use of a higher level ontology would seem the best way to approach the problem of offering a simpler high level access to MM data for processing and interpretation purposes. We are now investigating this solution.
Link:
http://www.muscle-noe.org (Workpackage 9)
Please contact:
Ovidio Salvetti, ISTI-CNR, Italy
Tel: +39 050 3153124
E-mail: Ovidio.Salvetti isti.cnr.it
isti.cnr.it
or Eric Pauwels, CWI, The Netherlands, (MUSCLE Scientific Coordinator)
Tel: +31 20 592 4225
E-mail: Eric.Pauwelscwi.nl