Managing the Growth of Multimedia Digital Content
by David Bainbridge, Paul Browne, Paul Cairns, Stefan Rüger and Li-Qun Xu
The growth in multimedia documents including collections of photos, music and videos etc has been phenomenal in recent years. Effective management of these multimedia collections has become a necessity for both businesses and the general public. Indeed with the advent of large volume and cheap storage devices and increasingly adopted broadband connections, home storage systems are becoming a reality for ordinary users to organise multimedia files. Current approaches - used mainly by fully trained professionals - are expensive and complicated. Can the media growth be effectively managed?
A multimedia digital libraries project has been set forward to address the complex issues related to media management with a view to developing more effective approaches for searching and browsing multimedia content: The Multimedia Information Retrieval group at Imperial College London collaborates with Human-Computer-Interaction experts from University College London, Digital Library experts from the Greenstone group at the University of Waikato, New Zealand, and Media Management experts at BT Research. The group is pulling together digital content from archives of the BBC, the British Library, the New Zealand Digital Library and the Victoria & Albert Museum.
This project has the following four main objectives:
- develop a query-by-example retrieval approach using automated content-based analysis, in conjunction with meta-data and text-based search when and if necessary
- devise new tailored search and browsing approaches appropriate for different media collections and users' needs
- reduce information overload by pre-senting and summarising search results in a semantically meaningful manner
- define new interfaces which can integrate and adapt to different media and user knowledge.
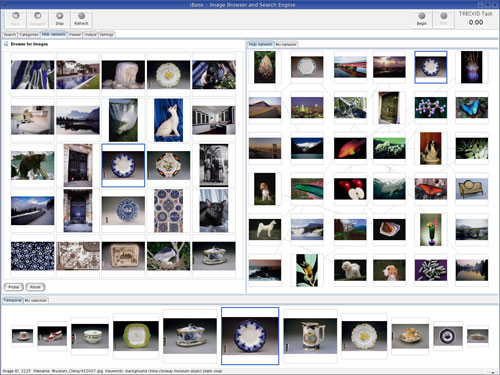
For example, we will automatically create new relations between multimedia objects (ie photos and videos segments) by automatically inserting links from each object to all those objects which are most similar under different criteria, thus creating a list of nearest neighbours with what we call ‘lateral associations’. This generates a network which is eminently suitable for browsing and exploration. The right panel in the figure summarises a large image database by displaying all highly connected images in the network; they can serve as entry points for browsing. The lateral neighbours of a particular image are shown in the left panel. The bottom panel shows objects in their context, which may be temporal in the case of videos or semantic (eg same category or genre) in the case of image collections.
Who really needs Multimedia Digital Library Management?
The beneficiaries of such a system include students and scholars, the medical profession with their specific databases and the general public. Organisations that create and manage digital libraries could also benefit; they include museums, art galleries, and photo & movie libraries. Indeed, even casual users are starting to see a need for an effective way to manage their growing collections of digital photos, music and personal movies.
The project is meant to have a defining impact on the way documents / information are presented and accessed in digital libraries. It aims to provide easy access to digitised material that is not yet fully annotated. Such methods are likely to ultimately change the way products, goods and services are presented in digital catalogues and how they are marketed on the Internet. It will revolutionise the design of large scale video databases as well as spawn a range of new revenue opportunities for museums, art galleries and image libraries.
Managing Future Multimedia Collections
Traditional libraries, digital or not, use meta-data, catalogues and classification systems to facilitate access to documents. Search engines such as Google have enhanced this process by indexing and searching the entire documents to give access to the meta-data, i.e., the link to the document. This project intends to go a step further by providing visual access modes, eg, through visual search boxes into which images can be dropped. Those visual access modes will be in addition to traditional meta-data search in libraries and full-text search boxes. As such, we amalgamate digital library functionalities given, eg by the successful Greenstone Digital Library (http://www.greenstone.org) with content-based multimedia access.
As applications evolve over time their functionality and user interface complexity tend to increase substantially. User interfaces do not generally offer different approaches for people having different individual characteristics (Novice, Intermediate, or Professional). Adaptable and responsive interfaces are important for the search and browse of media libraries.
Our Multimedia Collections
The multimedia digital libraries project development requires a diverse collection of media in order to design and evaluate appropriate search and browsing approaches according to users’ requirements. The varying levels of meta-data available within the collections will provide a realistic testbed for validating the underlying technologies. The test collections include the following:
- 50 hours of television content from the BBC
- 1 million page images from a selection of 200 newspaper titles supplied by the British Library
- the University of Waikato's Maori newspaper collection
- the V&A collection of 29,000 images with annotation
- Imperial College London's digital Shoebox collection of 6,000 personal photos.
The multimedia digital libraries project aims to solve the complex media management issues by offering a tailored browsing and search access that is adaptable to users’ needs as well as different digital library collections.
Software that arises from this project will become open source and will be disseminated under the GNU General Public License.
Link:
http://mmir.doc.ic.ac.uk/pr-mmdl-2005/
Please contact:
Stefan Rüger, Imperial College London, UK
E-mail: s.rueger imperial.ac.uk
imperial.ac.uk