Designing Multi-Modal Multi-Device Interfaces
by Silvia Berti and Fabio Paternò
The increasing availability of new types of interaction platforms raises a number of issues for designers and developers of interactive applications. There is a need for new methods and tools to support the development of Multi-Modal Multi-Device applications. The TERESA tool supports multi-modal user interfaces in multi-device environments.
Life today is becoming a multiplatform experience in which people are surrounded by different types of interactive devices, including mobile phones, personal digital assistants (PDAs), pagers, car navigation systems, mobile game machines, digital book readers, and smart watches through which they can connect to networks in different ways.
This situation poses a number of challenges for the designers and developers of multi-device interfaces. A further complication is that these devices can use different modalities (graphics, voice, gestures, and so on, in different combinations). Thus, although there are now a number of multimodal systems in circulation, their development still remains a difficult task.
A promising solution to handle the complexity involved is to use logical device-independent, XML-based languages to represent concepts, such as user tasks and communication goals, along with intelligent transformers that can generate user interfaces in different implementation languages for different platforms depending on their interaction resources and modalities.
We have developed an authoring environment, TERESA, within the EU IST project CAMELEON to address issues related to multi-device interfaces. An extension was implemented in the SIMILAR Network of Excellence on Multi-Modal User Interfaces in order to support multi-modal user interfaces in multi-device environments. TERESA incorporates intelligent rendering to decrease the cost of developing multiple interface versions for the different target platforms, allowing designers to concentrate on logical decisions without having to deal with a variety of low-level details at the level of implementation languages.
In the design and development process, it is important to consider that there are tasks that may be meaningful only when using some specific platform or modality. For example, watching a long movie makes sense in a multimedia desktop system, whereas accessing information from a car in order to avoid a traffic jam can be done only through a mobile device, and if this task is performed while driving, it can be supported only through a vocal interface. The modality involved may also impact on how to accomplish a task, for example vocal or graphical mobile phone interfaces require the user to perform tasks sequentially which could have been done concurrently in a desktop graphical interface.
In our approach, a user interface is structured into a number of presentations. A presentation identifies a set of interaction techniques that are enabled at a given time. The presentation is structured into interactors (logical descriptions of interaction techniques) and composition operators, which indicate how to put the interactors together. While at the abstract level, the interactors and their compositions are identified in terms of their semantics in a modality independent manner, at the concrete level their description and the attribute values depend on the modality involved.
In the case of both vocal and graphical support, multimodality can be exploited in different manners. Modalities can be used alternatively to perform the same interaction. They can be used synergistically within one basic interaction (for example, providing input vocally and showing the result of the interaction graphically) or within a complex interaction (for example, filling in a form partially vocally and partially graphically). A certain level of redundancy can also be supported, for example when feedback for a vocal interaction is provided both graphically and vocally. We have decomposed each interactor into three parts and the above properties can be applied to each part: prompt, represents the interface output indicating that the system is ready to receive an input; input, represents how the user can actually provide the input; feedback, represents the output of the system after the user input.
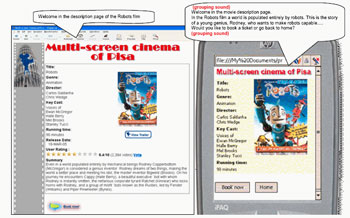
The composition operators indicate how to put such interactors together and are associated with communication goals. A communication goal is an effect that designers aim to achieve when they structure presentations. Grouping is an example of a composition operator that aims to show that a group of interface elements are logically related to each other. It can be implemented in the graphical channel through one or multiple attributes (fieldset, colour, location...), whereas in the vocal channel the grouping of elements is achieved by inserting a sound or a pause at the beginning and the end of the grouped elements. In the case of multimodal interfaces we have to consider the actual resources available. Thus, grouping on a multimodal desktop interface should be mainly graphical and the use of the vocal channel can be limited to providing additional information on the elements involved. Instead, the grouping for a multimodal PDA interface uses the vocal channel more extensively, while the graphical one is dedicated to important or explicative information (see Figure).
The current environment supports design and development for various types of platforms (form-based desktop, interactive graphical desktop, form-based mobile, interactive graphical mobile, vocal device, multimodal device) and generates the corresponding user interfaces in various implementation languages (XHTML, XHTML Mobile Profile, VoiceXML, SVG, X+V). Future work will be dedicated to supporting additional modalities, such as gestural interaction.
Links:
TERESA: http://giove.isti.cnr.it/teresa.html
SIMILAR Network of Excellence: http://www.similar.cc
HIIS Laboratory at ISTI-CNR: http://www.isti.cnr.it/ResearchUnits/Labs/hiis-lab/
Please contact:
Fabio Paternò, ISTI-CNR, Italy
Tel: +39 050 315 3066
E-mail: fabio.paterno isti.cnr.it
isti.cnr.it