Multimedia Indexing: The Multimedia Challenge
by Patrick Gros, Manolis Delakis and Guillaume Gravier
Multimedia indexing is a very active field of research, despite most works using only a single medium. This is mainly due to the fact that while they may be correlated, media are not strongly synchronized. Segment models appear to be a good candidate to manage such a desynchronization.
Multimedia indexing has become a general label to designate a large domain of activities ranging from image description to description languages, from speech recognition to ontology definition. Of course, these fields existed before the expression ‘multimedia indexing’ became popular, and most continue to have an independent existence. However, the rise of multimedia has forced people to try to mix them together in order to manage properly big collections of multimedia documents. The global goal of multimedia indexing is to describe documents automatically, especially those containing images, sounds or videos, allowing users to retrieve them from large collections, or to navigate these collections easily. Such documents, which used to be rare due to the price of acquisition devices and because of the memory required, are now flooding our digital environment thanks to the camera-phones, webcams, digital cameras, as well as to the networks that allow the data to be widely shared. The question is no longer “How can I acquire a digital image?”, but rather “How can I retrieve the image I want?”
What Does Multimedia Change?
While it is possible to study images or audio tracks alone for some documents, such approaches appear to be very limited when applied to multimedia documents like TV streams. This limitation is twofold. First, users (who are not specialists or documentalists) would like to access such documents semantically; second, users face huge sets of documents. As a consequence, many techniques that reduce semantics to syntactic cues in the context of small sets of documents are no longer useful, and no single medium can provide acceptable access to document semantics.
If one considers a TV stream, it is apparent that images are not able to provide a lot of semantic information. The information that can be extracted from this medium includes segmentation information (shot detection, clustering of neighbouring shots), face detection and recognition capabilities, and text and logo detection. It is possible to do a lot more but only in very limited contexts, like news reports or sports broadcasts. In such contexts, syntactic cues like outdoor/indoor classifications have a pertinent semantic translation (anchor person/outdoor reports), but these tricks cannot be used in open contexts. The situation is similar in audio analysis. Cries and applause are good indications of interesting events in sport reports, but not in drama and films. On the other hand, audio can provide useful segmentation information (music or speech detection), speaker detection and recognition, key sound detection, or speech transcription capabilities. There may be several sources of interesting text, eg internal sources like closed captions, text included in the images, speech transcription or external sources such as program guides.
The Big Challenge: Mixing Media
The best way to describe a document is to make use of all the information it carries, and thus all the media it includes. If this statement seems obvious, it nevertheless implies many practical difficulties. The various media within a document are not synchronized temporally and spatially: the speaker is not always visible on the TV screen, the text related to an image may not be the closest thing to this image, audio and video temporal segmentations have different borders. To make things worse, audio and video do not work at the same rate (100Hz for audio, and 24, 25 or 30Hz for video). From a more general point of view, audio, video and text are studied using different backgrounds, which are not always easy to mix. Text requires natural language-processing tools that use data analysis or symbolic techniques, while image and audio are branches of signal processing and use a lot of statistical tools but in the continuous domain. Other domains like geometry are also used. Mixing all these tools in one integrated model is one facet of the problem.
Two common solutions to this problem exist in the literature. The first is to use the media in a sequential manner. One medium is used to detect some event, and another medium is then used to classify it. For example, audio can be used to find the most important events in a soccer game, while video is necessary to understand what kind of event it is. Such an approach does not require a theoretical framework, remains ad-hoc and is not so difficult to implement, and is a good starting point for many problems. The second uses Hidden Markov Models (HMMs) to describe and recognize sequences of events. Markov models are of common use in sound and image processing and are very suited to identifying sequences of events. This is thanks to the Viterbi algorithm, which is based on a dynamic programming approach and provides a global optimal solution at a reasonable cost.
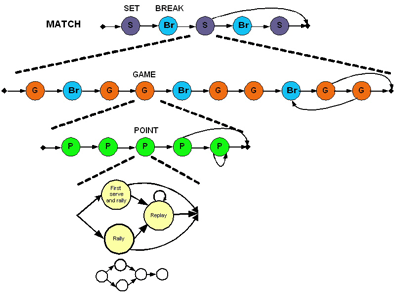
Segment Models: A Promising Approach
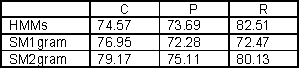
In the context of multimedia documents like video streams, HMMs have strong limitations due to the fact that each state may correspond to one and only one observation. On the other hand, this observation can contain a visual and an audio part. In the context of video documents, this means that a single temporal granularity must be chosen for the observations, and to align sound information on video units (images or shots) or vice versa. We used such models to retrieve the structure of videos of tennis, and despite the limitation, these models performed well in terms of precision of shot classification.
We propose using an enhanced version of these models called segment models (SMs). In these models, each state can accept a variable number of observations, this number (or its distribution) being a new parameter of the state. On the one hand, such a model allows a different number of visual and audio observations for a given audio-visual event. On the other hand, it adds some complexity to learning the conditional probabilities of the observations, and to identifying the duration of each state in the data streams. Our first results show that segment models can outperform Markov models. However, the main work is now to determine how much flexibility we can gain, and what can be done that was impossible before.