
 This issue in
This issue in 
A Light-Weight and Scalable Network Profiling System
by Andreas Kind, Paul Hurley and Jeroen Massar
Long-term network monitoring in high-speed networks requires new ways for collecting, storing and analyzing flow-based network traffic information. A project at the IBM Zurich Research Laboratory looked at alternatives to the conventional flow-based network profiling approach with the objective of improved scalability for high flow rates. The result is a light-weight and scalable network profiling system for NetFlow and IPFIX that is based on a novel time series aggregation database.
The continuing trend toward distribution of computing resources increases the need to tightly control the networks providing remote access to resources such as servers, storage and databases. An important means for controlling networks is network performance monitoring and, in particular, network profiling. A typical profiling system collects and analyzes information about the traffic flows passing an observation point in the network, eg, a router or traffic meter. A flow is a sequence of packets with common properties (ie, protocol and source/destination addresses/ports).
In the past, flow-based network profiling has proven to be useful for a number of applications, including network monitoring, billing and planning. To facilitate smooth operation of service access in distributed computing architectures (eg, SANs, computational Grids) the demand for profiling will continue to rise.
Other network profiling systems have a critical scalability problem regarding the storage, analysis and access of collected profiling information. Indeed, this was the primary motivation for the development of our approach. In high-speed networks with average flow rates of 1,000 flows/s and peak flow rates of as much as 20,000 flows/s, storage for 180 MB/h (3.6 GB/h at peak times) must be provided and maintained. Over longer time periods (ie, months, years), the data accumulates, resulting in an over-loaded system with slow reporting.
Time Series Aggregation Database
Our profiling approach addresses the scalability problem by using a novel aggregation database (ADB) for time series information. ADB provides a mechanism for efficient incremental storage of primary data values which are associated with time intervals. The database stores data values in groups of circular arrays of decreasing resolution and is, therefore, able to handle large time series data sets with fast access times and limited storage. ADB automatically assures that the array resolution of older data values is lower than the resolution of newer data values. Additionally, great care was taken with the design of ADB in order to reduce memory to disk synchronization and cache the relevant arrays in memory for fast data import and export.
Array grouping in ADB is efficient for obtaining a sorted view of related parameters. This feature is of great importance in our profiling tool for efficiently displaying sorted lists of top protocols, top hosts, top flows, etc.
ADB has a built-in array allocation optimization which further reduces the storage requirements. If an array is updated with values of progressing intervals, no preceding array space is allocated because it will never be needed. Furthermore, for insertion of new values, array space is only allocated in fixed chunks in order to avoid allocation of potentially unused array space. These optimizations reduce the required storage allocations considerably for only sparsely filled time series data streams. In network profiling, these optimizations are very useful when, for instance, a dynamically assigned IP address is only observed during a certain time period (eg, a week). In this case, space in a monthly array is only allocated around the actual observation period and not for the entire month.
Implementation
The developed system is the first profiling system we know of that implements the emerging IETF IPFIX standard. As such it supports IPv6 at data and control plane and can receive flow records over SCTP.
The reports show traffic information in graphs and tables regarding domains, protocols, QoS tags, hosts/servers, individual flows, packet and flow statistics, port/host scans and other networking aspects. The reporting period can be varied over many time scales. Custom zoom reports regarding specific traffic aspects can be generated on demand using a filter mask.
|
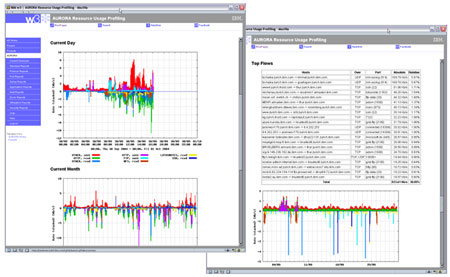
A typical problem in network profiling systems is that bursts of high flow rates can be caused by observed port or host scans. In these cases, a single packet may be considered a flow since no other proceeding packet will have the same properties with regard to the source/destination addresses and ports. The rate of the flow export can, under extreme circumstances, even exceed the data rate. Unfortunately, bursts of high flow rates can not only provoke flow table overflows at the observation points but may also render the analysis and storage to be no longer able to keep up with the incoming flow information. For these cases, we added an automatic mechanism to our system to aggregate flow records of a port or host scan into a single record.
The described profiling system, including the aggregation database (ADB), has been developed over the past two years. The system has been installed at a number of IBM locations and is currently being tested at two European ISPs. Snapshots of sample reports are shown in the figure.
Link:
http://www.zurich.ibm.com/sys/storage/resource.html
Please contact:
Andreas Kind, Paul Hurley and Jeroen Massar,
IBM Zurich Research Laboratory, Switzerland
E-mail: {ank,pah,jma}![]() zurich.ibm.com
zurich.ibm.com