| |
Deviation Detection of Industrial Processes
by Anders Holst, Jan Ekman and Daniel Gillblad
One of the major problems in complex processes is that it is impossible to foresee every possible type of fault or abnormal situation. This makes it hard to construct automatic fault detection systems, since it is impossible to know what to look for. An interesting approach to this problem is deviation detection, which turns the problem around by using learning systems to model 'normal' behaviour and then measuring the abnormality of a new situation against this.
The general approach for deviation detection is to construct a statistical model of the relevant features of the domain being monitored. The parameters of the statistical model are estimated using data consisting of (only or predominantly) normal cases. When used for detecting deviations, the model calculates the likelihood of a new sample case, ie, the probability that the model would generate that sample. A low likelihood signals that the sample is not likely to be drawn from the model of the normal data, and thus may be abnormal.
The area where this approach has received the most attention is in intrusion detection systems (IDS). Here, statistical methods are used to characterise traffic or user behaviour in various ways, based on variables such as traffic volume, distribution over time, types of accessed documents, multiple accesses to different servers etc. At SICS we have used a similar approach to create a system to detect fraud in ADSL-based pay-per-view systems in a project with TeliaSonera. A number of features from the domain, such as the number of ordered and billed films and the amount of outgoing and incoming network traffic, was used to train a mixture model to recognise normal (non-fraudulent) users. When tested on another set of normal users, plus a number of fraudulent cases of three different types (billing fraud, subscription fraud, and illegal redistribution fraud), the model successfully picked almost all of the billing and redistribution frauds, and the majority of the subscription frauds.
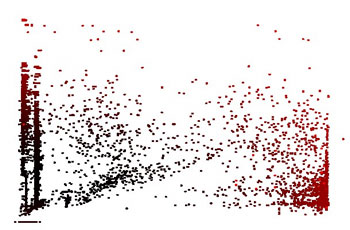 |
| A projection of the fraud detection data. The redness of the points indicates how unlikely they are (the negative log likelihood). |
Another application in which SICS is applying the same techniques is the detection of abnormal behaviour in ship movements based on radar images. The goal is to be able to generate a warning if a ship is moving in a strange, dangerous, or suspicious way. The relevant features that are modelled in this case include local properties, such as current position and speed, as well as more qualitative features of the route travelled so far, such as the number of turns, stops, possible encounters with other boats, and so on.
It is also becoming possible to embed such normality modelling into industrial systems such as network routers, industrial robots, the components of paper mills etc. This will make it possible for the components themselves to generate a warning when something is beginning to get out of order; for instance, in the context of condition-based maintenance, the components could indicate when they are close to wearing out and need replacement or service. Making components self-monitoring in this way has several advantages in terms of reliability, uptime, reduced waste of materials, and lower maintenance and production costs.
We are taking the first steps towards this in a project funded by SSF (Swedish Foundation for Strategic Research) and entitled 'An 'English butler' for the process industry'. One of the test cases is a Swedish hot steel rolling mill. There are many factors affecting the final quality of the steel, such as the form of the heating curve. By monitoring these factors, it is possible to detect when the process moves outside the normal region in state space, and hence when a risk of damage to the steel exists.
Critical for the success of deviation detection is the use of sufficiently powerful statistical learning models to catch relevant behaviour in often highly complex domains. At SICS we have developed a general statistical modelling tool, 'Hierarchical Graph Mixtures', based on a combination of mixture models, probabilistic graph models, and Bayesian statistics. This has given us a very powerful and flexible framework for modelling, which is applicable to a wide range of real-world tasks.
Links:
http://www.sics.se/iam/projects/butler.html
http://www.sics.se/iam/projects/adaf.html
http://www.sics.se/iam/projects/dallas/dallas.html
Please contact:
Anders Holst, Jan Ekman, Daniel Gillblad, SICS
E-mail: aho sics.se, jansics.se, dgisics.se sics.se, jansics.se, dgisics.se
|


