| |
Environment Representations for Cognitive Robot Companions
by Ben Kröse
World representations for intelligent autonomous robots are studied at the University of Amsterdam. An omni-directional vision system is used in combination with appearance modelling for robot localization and navigation. The goal is to develop a robot interface between human and intelligent environment. Also robot learning of concepts by interaction with humans is investigated.
An increasing amount of research is spent on robots that operate in natural, non-industrial environments and interact with humans such as household robots, sociable partners, education robots or personal assistants. Since the natural environment is highly unstructured and possibly unknown, these robots cope with the problem of learning an internal model of this environment. Furthermore, since these robots are to interact with humans in a natural way, the representation should correspond with human concepts of space.
At the Informatics Institute of the University of Amsterdam several research projects are focussed on world representations for intelligent autonomous systems. Such systems perceive the environment, reason about it, and act in it. An internal representation is needed for planning and navigation. For example, if a household robot is instructed to vacuum the kitchen, it needs to use the internal model to plan a path from its current location to the kitchen.
Conventional industrial mobile robots use geometric models, like polygons or occupancy grids, which fit very well with the range sensors traditionally used on these types of robots. Although adequate for industrial environments, which are generally simple and have a regular structure, more powerful models are needed for natural environments like houses, of which the structure may be complex and not easy to describe with simple geometric primitives. In many cases also other characteristics of the environment such as colour or texture need to be modelled, which may be a more powerful cue for robot location than geometric properties. Luckily today's developments in computational power and sensor technology open a way for the use of vision systems on mobile robots. We investigated whether a vision system can also be used for robot localization. Can the robot 'see' where it is?
In our studies we use an omni-directional vision system, which is able to capture images of the full surroundings at video rate. The issue that arises is which type of internal representation is best suited for the (navigation) task of the robot and which best corresponds to our visual sensor. One approach is to use a full CAD model, which combines the geometry of the environment with intensity and colour. However, such models are difficult to derive from visual information. We took an alternative approach where we do not explicitly model the environment, but made an implicit environment representation by modelling the relation between the observed image and the robot location. This is called 'appearance' modelling. Such a model can be learned more easily than a CAD model, and we showed that it is well suited for the navigation task.
In appearance modelling a large set of images taken at different locations is stored. For our office environments we typically use about 1000 images. A problem with modelling in the image space is the high dimensionality of the data. Our omni-directional images are typically 64 x 512 pixels, so an image is a vector in a 32K-dimensional space. We therefore first reduce the dimensionality of the images with a Principal Component Analysis (PCA), and store the linear features. For robot localization we use a probabilistic framework. The current observation of the robot is compared with the database and the likelihood of the observation is determined. Since the likelihood is conditioned on the location of the robot, we can determine the posterior probability distribution of the robot position by using Bayes rule and the prior distribution of the robot positions, which is estimated from the previous estimate. The localization procedure is schematically depicted in Figure 1. An important part of the research project is to find a computationally efficient way to represent the probability distributions. We used a special variant of a Monte Carlo 'particle' filter.
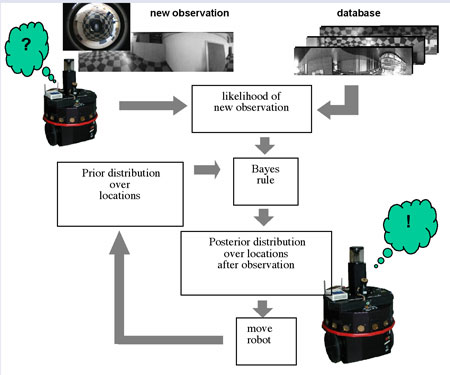 |
| Figure 1: The Markovian robot localization. To calculate the likelihood of a new observation, a kernel estimator is used on the images from the database. The distribution of the robot location is implemented as a Monte Carlo method. |
This method was developed within a large project funded by the Japanese MITI, in which we collaborated with various Japanese research laboratories, and was successfully demonstrated at various fairs and exhibitions. Currently the research is continued in a European project on Ambient Intelligence, in cooperation with Philips, Epictoid (a CWI spin-off) and many other European partners. Here the goal is to make a robot, which serves as interface between the human and the intelligent environment. Such a robot must be able to navigate in the home environment and to interact with humans in a natural way by speech understanding, speech synthesis and an expressive face. In this project we use the appearance modelling approach for localization and navigation.
 |
| Figure 2: Left: the mobile robot with the omnidirectional vision system. The properties of of the hyperboloid mirror enable an omnidirectional image (upper right) to be reprojected easily onto other surfaces, for example onto a virtual cylinder, resulting in a panoramic image (bottom). |
Although this type of environment modelling is a step further on the way to a more natural representation, we do not have yet the concepts, which can be used to communicate with humans. In a project funded by the Netherlands Organization for Scientific Research NWO we investigate whether the robot can learn 'concepts' by interaction with humans. The objective of the project is to develop learning methods, which are able to form 'state-action' concepts, such as: 'go to the door, then left, then after the second fire extinguisher right', or 'perceptual' concepts, such as: 'corridor', 'hallway' or 'window'. Again we use the omni-directional vision system, and we developed fast learning methods to enable real-time learning. The first experiments show promising results, and we hope to have a robot, which learns elementary concepts in a short training time. The challenge is to show that an embodied intelligent agent is able to learn concepts by navigating in real environments and interacting with humans.
Please contact:
Ben Kröse, University of Amsterdam, The Netherlands
Tel: +31 20 525 7520/7463
E-mail: krose@science.uva.nl
http://www.science.uva.nl/~krose/
|


