| |
Concepts on Enriching, Understanding and Retrieving the Semantics on the Web
by Arne Sølvberg, Sari Hakkarainen, Terje Brasethvik, Xiaomeng Su, Mihhail Matskin and Darijus Strasunskas
The COEUR-SW program at the Department of Computer and Information Science at NTNU in Norway seeks to capture the heart of the Semantic Web.
The Information Systems on the Web comply with the semiotic triangle. In the COEUR-SW triangle, a concept in a Universe of Thought is related to an uttered symbol in a Universe of Language, the symbol is related to a referent in a Universe of Structure, and the referent is related back to the concept. The concept, the symbol and the referents are related to a context in the Universe of Discourse (UoD), as embedded in the Web. The COEUR-SW program approaches the UoD from three interrelated angles and thus seeks to capture the heart of the Semantic Web.
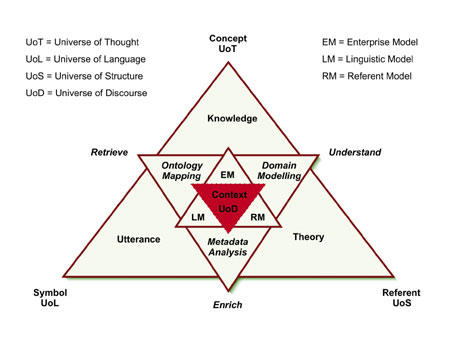 |
| The COEUR-SW program at IDI, NTNU in Norway, approaches the UoD from three interrelated angles. Domain modelling is used in order to capture the knowledge within a UoT into a man/machine understandable theory in a UoS. Ontology Mapping is used in order to capture the utterances in a UoL into man/machine-retrievable knowledge. Metadata analysis is used in order to capture the theories in a UoS into enriched man/machine generative utterances in a UoL. In all the approaches inter-related conceptualisation of the UoD is used in order to capture the heart of the Semantic Web. |
The Web has three major roles in Information Systems; one role as the dominant medium for information dissemination, one as the tool for information compilation, and one as the evolving information repository. The roles comprise enterprise and user interface issues (UoT), information categorisation and interpretation issues (UoS), and information storage and information access issues (UoL).
In order to support dissemination and compilation of information, the repositories may be organised according to the principles of integration or interoperability. In the former, the relevant information repositories are viewed as one large distributed database, organised according to a common schema. In the latter, every information system is considered to consist of autonomous subsystems.
The integration principle is dominant in the classical approaches to information systems design. The alternative principle of semantic interoperability is more compliant with the Semantic Web. For interoperable systems to communicate there must be some agreement on coding as well as meaning of data, but only for the data that is interchanged. The mutual understanding must be as wide as it is necessary for a particular data interchange, but need not be wider.
Semantic Interoperability
Data semantics is the relationship between data and what the data stand for. In order to obtain mutual understanding of interchanged data, the actors have to share a model of what the data represent. Semantic interoperability is about how to achieve such mutual understanding.
In order to achieve this we use concepts and symbols. The concept is the unit of thought. The symbol is the unit of language. Theories, such as Newton's theory of motion, are structures of thoughts, and referents like force, mass and acceleration are the units of these structures. Conceptual knowledge comes wrapped in symbols, eg mathematical notation, words or diagrams, which are the linguistic expressions of knowledge. In order to access the ideas of other people, ie the concepts in their UoT, we must understand the conceptual structures that are employed in the common UoS. Furthermore, we need to understand the relationship between the symbols and the ideas they stand for.
Agent Systems
Agents in a multi-agent system are characterised by abstraction, interoperability, modularity and dynamism. These qualities are particularly useful in that they can help to promote open systems, which are typically dynamic, unpredictable, and highly heterogeneous, as is the Internet.
Within a multi-agent system, agents represent their 'view of the world' by explicitly defined ontologies. The interoperability of such a multi-agent system is achieved through the reconciliation of these views by a commitment to common ontologies that permit agents to interoperate and cooperate. However, between different agent systems, ontologies are developed and maintained independently of each other. Thus two agent systems may use different ontologies to represent their views of the domain. This is often referred to as an ontology mismatch. In such a situation, interoperability between agents is based on the reconciliation of their heterogeneous views.
Web Resources
Recently, several general-purpose models for describing Web resources have emerged. The intention of the industry-driven initiatives is to provide a metadata description framework for interconnected resources. A resource can be viewed as a bibliographic document (DC, MARC), electronic Web resource (RDF, HTML) multimedia object (SMIL), ontology (OIL, DAML), database concept (MDIS, OIM), or case tool structure (XMI). Many of the models result from standardisation work as carried out in industry-driven coalitions like W3C, MDC, and OMG.
Emerging academic research work has adapted and applied some of the models provided by the industry coalitions. Metadata is recognised as equally important for describing the components from which we build services and systems, regardless of whether they are on the Internet or not. The research so far has focused on technical aspects of the frameworks, semantic coverage of the models, and reasoning and querying mechanisms. The area is becoming mature enough for comparative studies and prescriptive theories on the proposed modelling frameworks.
Activities
The overall intention of the COEUR Semantic Web research program at IDI, NTNU is to explore and exploit existing research results in the areas of conceptual modelling, information systems analysis and design, agent technology, and information systems architectures. Our attacking point is semantic interoperability. Our main armoury consists of enriched descriptions and representations for each of the Universes of the Semantic Web triangle. Our ultimate target is to enable information systems development for Semantic Web applications in areas such as information services, e-commerce, knowledge management, and cooperative systems.
Currently, several activities are under way within this program:
- the Referent Modelling Language project, RML
- the Ontology Mapping Using Text Categorisation project, OMUT
- the Semantic Modelling of Documents project, SeMDoc
- Conceptual Metadata Analysis and Design in Information Service Development, COMAD
- the Adaptive Distributed Information Service project, ADIS
- the Traceability in Cooperative Systems Development project, CoTracSyDev.
Links:
http://coeur-sw.idi.ntnu.no/
http://coeur-sw.idi.ntnu.no/rml/
http://coeur-sw.idi.ntnu.no/semdoc/
http://coeur-sw.idi.ntnu.no/comad/
http://coeur-sw.idi.ntnu.no/adis/
http://coeur-sw.idi.ntnu.no/cosy/
Please contact:
Arne Sølvberg, NTNU
Tel: +47 7359 3438
E-mail: asolvber@idi.ntnu.no
|



