Integrating Multimedia Components into a Semantic Web
by Benjamin Jung and Lyndon JB Nixon
The concept of separating content, transformation and presentation data is one of the key requirements for constructing a Semantic Web. It has been successfully applied in textual publishing for decades (using SGML and DSSSL) and could finally revolutionise composition and access of multimedia components such as graphics, audio and video. What role does XML play in integrating multimedia seamlessly into a Semantic Web?
During the electronic publishing process content passes through a number of conversion layers. Each layer modifies the content to adjust and customise it in more detail to create user-oriented valuable information. The reverse generalisation process is used to break up documents into basic and original components such as content, transformation and presentation data. Traditional Web formats (ie HTML) no longer allow reverse engineering of information, as all components are unidentifiably blended together.
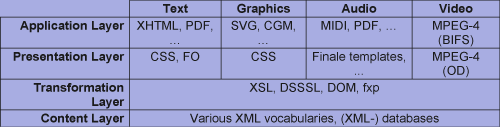
The Table shows the four basic layers and exemplarily some of the vocabularies available. Each layer corresponds to one distinct stage in the publishing process. Vocabulary-specific processing engines are use to handle the data (eg XSLT engines to process XML documents with XSLT style sheets).
The physical storage and content data-source is represented by the Content Layer; the Transformation Layer physically changes the original content by adding, deleting (filter), modifying (process) and converting the content into a data format supported by the end user application. The Presentation Layer defines and adds style and rendering information, used by the application to sense (read, listen, watch) the final publication. The Application Layer finally represents all applications, capable of presenting information according to users' preferences.
 |
| Publication architecture. |
To cater for seamless and automatic integration of local resources into a Semantic Web, content has to be available independently from its transformation and presentation data. XML in combination with XML-related vocabulary specifications (see Table) offers a solid framework to organise and keep content, transformation and presentation data separately and in the most accessible way.
The definition of content, transformation and presentation data might be obvious in the context of textual publishing, but how are these components defined in graphical, audio and video publications, to become part of a Semantic Web?
Graphics
Images using raster graphics formats such as JPEG and GIF are widely used on the Internet. They are composed of a two-dimensional grid of pixels, the basic unit of programmable colour. While this makes information retrieval in terms of colour feasible, accessing other image information such as objects, shapes and relations is ambiguous if not impossible. For purposes of decomposition, images using raster technology are comparable with badly designed HTML pages, where content and presentation data is welded together, and it is impossible to extract pure content for further processing.
One XML-based solution to describing vector graphics is the SVG format, a sequence of mathematical statements that places lines and shapes into a two-dimensional space. It clearly defines the contents of the image (mathematical objects as well as their grouping) and its transformation in terms of location, size, applicable filters and deformations. An optional CSS file keeps presentation data such as colours and margins.
Audio
Separating content from presentation data in audio files appears to be more complex than it is for textual or graphical data. Traditionally, audio was distributed to the user as a single source (eg cassette, CD). Nevertheless, professional recording studios use single tracks for each instrument/voice and compile them together before distribution. One approach with an emphasis on audio delivery over the Internet is MusicXML, which uses XML to describe sheet music. Ideally, presentation data such as speed, volume, key and instruments will be kept separate from the MusicXML content file. Possible 'presentation engines' for MusicXML would include a sheet music renderer (for print) as well as an audio player.
Video
Video is the greatest challenge for content and presentation separation. 'Shaped video' is already used by TV studios to blend video objects together ; eg in weather forecasts, the weather forecaster and the background map are generated separately. However, object extraction from the result video stream is difficult. MPEG-4 is an ISO/IEC standard for the composition of audiovisual scenes consisting of both natural and synthetic media. While the format is binary, there is an XML representation for content interchange. With MPEG-4's Binary Format for Scenes (BIFS), multiple arbitrarily shaped video objects may be composed in an audiovisual scene together with video-quality synthetic images. The presentation of each video object is defined in an 'object descriptor' (OD) which includes decoding information, synchronisation and support for scalability. As objects in a BIFS scene can be manipulated individually, MPEG-4 offers the possibility of extending media adaptation into the realm of video. Furthermore, MPEG-4 has an XML representation for content interchange, which allows it to be tightly integrated with the Semantic Web. Lyndon's research is using XML-encoded metadata to dynamically generate MPEG-4 scenes, which, using shaped video techniques, would make adaptive video possible.
XLink
XLink, the next generation linking and part of the XML family of specifications, plays an important role for seamlessly integrating multimedia components into a Semantic Web. Having used the aforementioned concepts of separation, XLink allows link sources and targets to be defined in any granularity, eg ranging from a single letter to a paragraph (text), from a single line to the grouping of objects (graphics), from a single note to a set of measures (audio) and from a single frame to an entire scene (video).
Please contact:
Benjamin Jung, Trinity College Dublin
Tel: +353 608 1321
E-mail: benjamin.jung@cs.tcd.ie
Lyndon JB Nixon, Fraunhofer FOKUS
Tel: +49 30 3463 7103
E-mail: nixon@fokus.gmd.de
|



