| |
Hypermedia Presentation Generation on the Semantic Web
by Lynda Hardman
The research goal of the Multimedia and Human-Computer Interaction group at CWI is to investigate the automated generation of Web-based hypermedia presentations tailored to the abilities, preferences and platform of the user. This requires the description and processing of different types of information in order to assemble semantically annotated media items into a coherent presentation, ie a presentation that communicates the intended semantic relations to the user.
In text, these semantics are often implicit in the text-flow. In multimedia, however, the semantic relations among the media items need to be communicated explicitly by choosing appropriate layout and style. The assumption underlying current style sheet technology (XSLT and CSS), stating that content and presentation are independent, is often an oversimplification for multimedia presentations. In addition, current style sheets operate on the syntactic XML level and are unaware of the new generation Semantic Web languages, such as RDF(S) and OWL.
Creating well-designed multimedia presentations requires an understanding of both the presentation's global discourse and interaction structure as well as the intricate details of multimedia graphic design. In addition, knowledge of a number of other factors is needed. A domain description allows the relationships among domain concepts to influence the layout and links within the presentation. Knowledge about the user's task or environment allow appropriate choices of media to be made. In conjunction with information stored in the domain model, presentations can be generated, for example, to skip things the user already knows and explain new concepts in terms of already known concepts. A description of the characteristics of the end-user platform (such as screen resolution, bandwidth, ability to display colour, audio capabilities) allows optimal use to be made of the capabilities of the device.
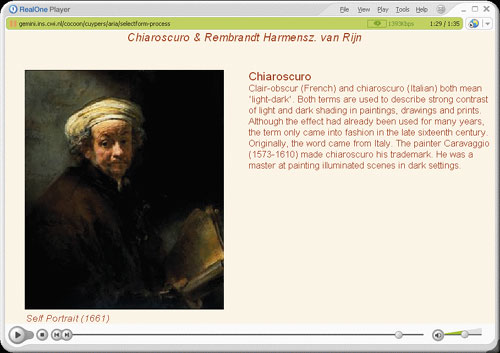 |
| Based on the annotated media database of the Rjiksmuseum in Amsterdam, the Cuypers engine automatically generates multimedia presentations in SMIL in response to user queries. The figure illustrates a presentation about the painting technique 'chiaroscuro' in the context of the work of the painter Rembrandt van Rijn. The presentation consists of a slide show with examples of paintings by Rembrandt using the chiaroscuro technique, alongside a textual explanation of the technique itself. While consisting of a number of individual media items returned by the database, the presentation is intended to convey the semantic relations among them.
For example, domain-independent layout knowledge is used to place the presentation title centrally, because it applies to both the slideshow and the textual explanation. In contrast, the title of the textual explanation is left-aligned with the body text to indicate that it refers only to that paragraph. The close proximity of the text 'Self Portrait (1661)' to the image, is intended to convey that the text is a label referring to the painting. In addition, explicit knowledge of domain-specific presentation conventions allows the engine to display it in such a way that the user can interpret it as being the painting's title and the year of creation. This work is carried out in the context of the Dutch ToKeN2000 project.
|
Our prototype generation engine, Cuypers, allows the specification of these different information types and incorporates them within the overall process of generating a presentation. In order to make the different knowledge sources explicit for use by the system we wish to use standard languages and tools. Given the range of tools available for the Web, incorporating Semantic Web tools and languages was a forgone conclusion. This allows us to re-use, for example, domain descriptions created by experts in the field, in a language with readily available processing tools. In addition, having generated a presentation, we are able to include semantic mark-up within it, thus capturing the knowledge used during its generation, eg which domain concepts media items correspond to, or platform profiles for which the presentation is suited. The current focus of our work is on creating a more realistic user model, developing a graphic design model and investigating the requirements for a discourse model.
Most work currently being carried out for the Semantic Web concentrates on the underlying semantics and is not concerned with presentation 'details'. On the other hand, most presentation tools on the Document Web operate only on the syntactic level. The long-term goal is the development of 'Smart Style', ensuring that both Semantic and Document Webs are integrated.
Links:
http://www.cwi.nl/ins2/
http://www.token2000.nl/
Please contact:
Jacco van Ossenbuggen, Lynda Hardman, CWI
Tel: +31 20 592 4141
E-mail: Jacco.van.Ossenbruggen@cwi.nl
|



