Corporate Semantic Webs
by Rose Dieng-Kuntz
The ACACIA multidisciplinary team at INRIA-Sophia-Antipolis is working towards offering methodological and software support (ie models, methods and tools) for knowledge management (ie for building, managing, distributing and evaluating a corporate memory) for an organisation or community. This corporate memory can be materialised in a 'Corporate Semantic Web' consisting of ontologies, resources (such as documents or persons) and annotations, possibly with modelling of multiple viewpoints.
We make an analogy between the corporate memory and the open World Wide Web: both are heterogeneous and distributed information landscapes and share the same problem of information retrieval relevance. In contrast, however, corporate memory has a context, an infrastructure and a scope limited to the organisation in question.
As research on the Semantic Web aims to make the semantic contents of the Web interpretable by software, we propose to materialise a corporate memory as a 'Corporate Semantic Web', constituted of ontologies, resources (ie documents or humans) and semantic annotations on these resources (ie on the document contents or the person features/competences), where these annotations rely on the ontologies.
We are studying the main research problems raised by such a 'Corporate Semantic Web':
- how to detect organisational needs, and whether to build the Corporate Semantic Web and each of its interrelated components from several human experts or from texts (cf methodology and architecture)
- how to diffuse and use the memory (information retrieval vs proactive dissemination)
- how to evaluate and evolve the memory (from both designer and user viewpoints).
Ontology and Annotation Construction
For the construction of ontologies, the CoMMA method integrates:
- a top-down approach relying on a synthesis of existing ontologies
- a bottom-up approach so as to exploit the (possibly partly automated) analysis of corporate documents or of human experts' interviews guided by scenarios
- a middle-out approach relying on generalisation and specialisation of key concepts of the organisation.
We used this hybrid method to build the O'CoMMA ontology (see below), dedicated to organisational memory and to scenarios such as newcomer insertion or technological monitoring.
As several corporate information sources can help to build an ontology (eg human experts, textual or multimedia documents, databases with possibly textual data), the SAMOVAR method and system rely on partly automated construction and enrichment of ontologies and of annotations from heterogeneous information sources, by applying natural language processing tools on textual sources. SAMOVAR was applied to project memory in the automobile industry.
Ontology and Annotation Representation
As several languages can represent ontologies and annotations in a Corporate Semantic Web, the cooperative project ESCRIRE with the EXMO and ORPAILLEUR teams enabled us to compare three knowledge representation (KR) formalisms (conceptual graphs (CG), object-based KR and description logics), from the standpoint of the representation and the handling of document content. Our team focused on the CG formalism.
In order to palliate some limitations of RDFS for ontology representation, we proposed DRDFS, an extension of RDFS which enables the expression of explicit definitions of concepts and of relations, as well as contextual knowledge. We also proposed the GDL language, a description logic inspired by conceptual graphs.
CORESE Semantic Search Engine
RDF, recommended by W3C, allows the contents of documents to be described in the form of metadata resting on an ontology represented in RDF Schema (RDFS). We developed CORESE (COnceptual REsource Search Engine), an RDF(S) engine based on conceptual graphs. It enables an RDFS ontology and RDF annotations to be loaded and translated into CG, and then, thanks to the CG projection operator, allows the base of annotations to be queried. CORESE also reasons on properties of relations (symmetry, transitivity, etc) and on XML-based inference rules, so as to complete the annotation base. CORESE was used in the projects Aprobatiom, CoMMA, ESCRIRE and SAMOVAR, and allows ontology-guided information retrieval in a 'Corporate Semantic Web'.
The CoMMA project: Corporate Memory Management through Agents
Heterogeneity and distribution of multi-agent systems can be a solution to heterogeneity and distribution of a corporate memory. In the framework of the IST project CoMMA (with ATOS, CSTB, LIRMM, the University of Parma and T-Nova), we proposed a multi-agent architecture for the management of a Corporate Semantic Web, enabling ontology-guided information retrieval (the 'pull' approach) and proactive dissemination of information to users according to their profiles (the 'push' approach). We distinguish agents dedicated to ontologies, to documents, to users and to interconnection between agents. The agents are guided by the O'CoMMA ontology, a corporate model and user models. Some agents have learning capabilities and can adapt to the users.
We have also developed algorithms for learning ontologies incrementally from RDF annotations on (corporate) Web resources. This method can be used to build classes of documents automatically from their annotations.
Two scenarios were studied: the insertion of new employees and technological monitoring. The CoMMA system, implemented in JAVA on the FIPA-compliant multi-agent platform JADE, integrates our search engine CORESE.
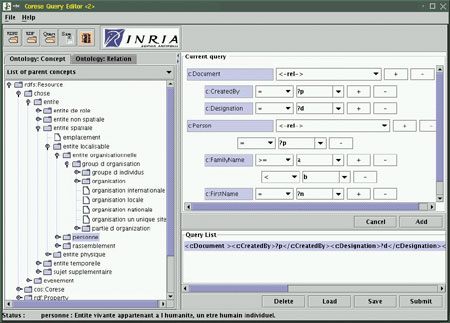 |
| Figure 1: CORESE semantic search engine interface. |
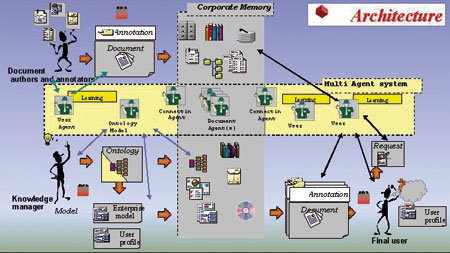 |
| Figure 2: Corporate Memory Managements through Agents - CoMMA architecture. |
Applications and Further Work
Our work on Corporate Semantic Webs was applied to project memory, technological monitoring, knowledge servers in the automobile industry (Renault), in the construction sector (CSTB), in telecommunications (T-Nova, TILAB) and in the biomedical domain. We also take part in the IST thematic network OntoWeb (Ontology-Based Information Exchange for Knowledge Management and Electronic Commerce).
In further work we intend to study a corporate memory distributed among several cooperating companies or communities. This memory will be materialised through a Semantic Web operating between organisations or communities, possibly handling multiple ontologies and multiple viewpoints and possibly requiring Web mining, for scenarios including project memory, technological monitoring and skills management.
The work described above was carried out by Olivier Corby, Alexandre Delteil, Rose Dieng-Kuntz, Catherine Faron-Zucker, Fabien Gandon, Alain Giboin, Joanna Golebiowska and Carolina Medina-Ramirez.
Links:
http://www.inria.fr/Equipes/ACACIA-eng.html
http://www.inria.fr/acacia/Publications
Please contact:
Rose Dieng-Kuntz, INRIA
Tel: +33 4 92 38 78 10
E-mail: Rose.Dieng@sophia.inria.fr
|



