| |
The ICS-FORTH RDFSuite: High-level Scalable Tools for the Semantic Web
by Sofia Alexaki, Nikos Athanasis, Vassilis Christophides, Greg Karvounarakis, Aimilia Maganaraki, Dimitris Plexousakis and Karsten Toll
RDFSuite addresses the need for effective and efficient management of large volumes of RDF metadata as required by real-scale Semantic Web applications.
In the next evolutionary step of the Web, termed the Semantic Web, a vast number of information resources will be made available along with various kinds of descriptive information, ie metadata. The Resource Description Framework (RDF) enables the creation and exchange of resource metadata as normal Web data. To interpret these metadata within or across user communities, RDF permits the definition of appropriate schema vocabularies (RDFS). Managing voluminous RDF description bases and schemas with existing low-level APIs and file-based implementations does not ensure fast deployment and easy maintenance of real-scale Semantic Web applications (eg Knowledge Portals and E-Market-places). Still, we would like to benefit from database technology in order to support declarative access and logical and physical RDF data independence. This is the main design choice of RDFSuite, which comprises the Validating RDF Parser (VRP), the Schema-Specific Data Base (RSSDB) and an interpreter for the RDF Query Language (RQL). It was developed in the context of the IST projects C-Web and MesMuses, both coordinated by INRIA. The Figure depicts the architecture of RDFSuite, which is available for download under an Open Source Software License from http://139.91.183.30:9090/RDF/.
The Validating RDF Parser (VRP) is a tool for analysing, validating and processing RDF schemas and resource descriptions. The Parser syntactically analyses the statements of a given RDF/XML file according to the RDF Model & Syntax Specification. The Validator checks whether the statements contained in RDF schemas and resource descriptions satisfy the semantic constraints derived by the RDF Schema Specification (RDFS). Unlike other RDF parsers, VRP is based on standard compiler generator tools, namely CUP and Jflex, which ensure good performance when processing large volumes of RDF descriptions. VRP has been successfully used with RDF schemas from existing Semantic Web applications, hosted by the Schema Registry at http://139.91.183.30:9090/RDF/Examples.html.
VRP supports embedded RDF in XML or HTML documents, XML Schema Data Types and Unicode character set. Users can activate or deactivate semantic constraints against which validation is performed and configure the parser according to their needs. Another substantial feature is the fetching of remote namespaces and their integration in VRP's internal RDF model. VRP provides various options for debugging, serialisation under the form of triples or graphs and complete statistics of validated schemas and resource descriptions.
The RDF Schema-Specific Data Base (RSSDB) is a persistent RDF Store for loading resource descriptions in an object-relational DBMS by exploiting the available RDF schema knowledge. It preserves the flexibility of RDF in refining schemas and enriching descriptions at any time, and can store resource descriptions created according to one or more associated RDF schemas. Its main design goals are the separation of the RDF schema from data information and the distinction between unary and binary relations holding the instances of classes and properties respectively. The experiments we have carried out illustrate that RSSDB yields considerable performance gains in query processing and storage volumes as compared to triple-based RDF Stores.
RSSDB has been implemented on top of the PostgreSql ORDBMS. It comprises Loading and Update modules, both implemented in Java. Access to the ORDBMS relies on the JDBC interface. Its most distinctive feature is the customisation of the database representation according to the employed meta-schemas (RDF/S, DAML-OIL), the peculiarities of RDF schemas and description bases and the target query functionality. The RSSDB Loader supports incremental loading of distributed namespaces by automatically detecting changes in already stored RDF schemas or data.
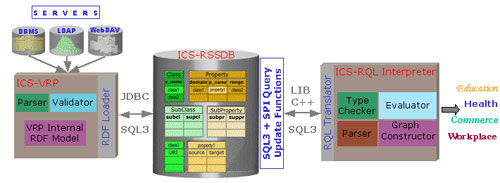 |
| RDFSuite architecture. |
RQL is a typed language, following a functional approach. RQL relies on a formal graph model that captures the RDF modeling primitives and permits the interpretation of superimposed resource descriptions by means of one or more schemas in various application contexts (recommendations, content ratings, push channels, etc). The novelty of RQL lies in its ability to seamlessly combine schema and data querying.
The RQL Interpreter has been implemented in C++ on top of PostgreSql using a standard client-server architecture for Solaris and Linux platforms. It consists of three modules: (a) the Parser, which analyses the syntax of queries; (b) the Graph Constructor, which captures the semantics of queries in terms of typing and interdependencies of involved expressions; and (c) the Evaluation Engine, which accesses RDF descriptions from the underlying database via SQL3 queries. It supports XML Schema data types, grouping primitive aggregate functions and recursive traversal of class and property hierarchies. It is easy to couple with commercial ORDBMSs as well as to integrate with various Web Application Servers. Finally, it provides a generic RDF/XML form of query results that can be processed by standard XSL/XSLT scripts.
Links:
http://139.91.183.30:9090/RDF/
http://139.91.183.30:8999/RQLdemo/
Please contact:
Vassilis Christophides, Dimitris Plexousakis
ICS-FORTH
Tel: +30 810 3916 28, 3916 37
E-mail: {christop,dp}@ics.forth.gr
|



