|
|
|
||||||
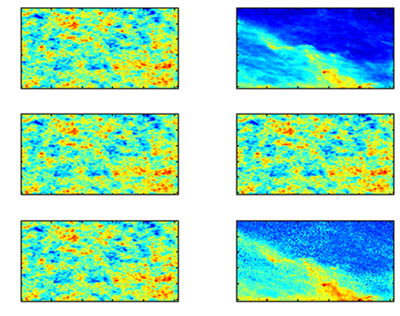
Blind Image Analysis helps Research in Cosmologyby Emanuele Salerno, Luigi Bedini, Ercan Kuruoglu and Anna Tonazzini Blind image processing techniques are being studied at IEI-CNR, with the aim of extracting useful information from satellite radiometric maps of the celestial sphere. This activity is undertaken on behalf of the European Space Agency Planck Surveyor Satellite programme. The Planck mission, to be launched in February 2007, will produce a very large amount of data, in the form of maps of the entire celestial sphere in the millimeter and submillimeter-wave bands. Its main goal is to map the cosmic microwave background (CMB) anisotropy with unprecedented angular resolution and sensitivity. It is known that CMB is a relic radiation coming from an epoch very close to the big-bang. Studying its anisotropy will provide important information on the origins and evolution of the universe. The antenna temperatures measured by the satellite-borne radiometers are generated both by CMB radiation and by other astrophysical processes, whose effects are superimposed on the maps. Whereas the interest of cosmologists is focused on CMB, all the processes mapped are of interest in astrophysics and should thus be separated out. The problem can be briefly formulated as follows: the data set is given by a number of sky maps, each on a different frequency channel; each map is a linear mixture of the maps related to the individual physical processes (source processes); the mixing coefficients depend on frequency through the source emission spectra and the frequency responses of the radiometers over the different measurement channels. Our objective is to separate the individual sources from knowledge of the mixed maps on all the channels. There are two main reasons why this is difficult. First, the mixing coefficients are normally not known; second, the sensor noise is expected to be particularly strong because of the very small quantities (tens of microkelvin) that are to be measured and nonstationary, due to the uneven sky coverage of the Planck telescope scanning strategy.
One approach to this problem assumes that the mixing coefficients are perfectly known. However, this does not guarantee a good result, especially when the matrix assumed is significantly different from the actual matrix and the noise is particularly strong. The ideal solution should come from a totally 'blind' approach, ie, from trying to estimate both the source maps and the mixing coefficients from knowledge of the measured data alone. Clearly, this is not possible, since the problem is underdetermined, but the data model (ie, the mixing coefficients) is not the only place where we can exploit prior knowledge. Indeed, the different radiation processes in the sky are very likely to be statistically independent. Moreover, with the exception of the CMB, the different radiations can be modeled as nongaussian processes. The Independent Component Analysis (ICA) principle states that, if a number of independent random processes are linearly combined, a linear operator can be applied to the mixed data in order to obtain independent outputs. If all the source processes, except at most one, are nongaussian, the outputs of the linear operator are copies of the original source processes. On the basis of this principle, or an equivalent one, different blind separation approaches can be adopted. These approaches are characterized by explicit or implicit assumptions on the component distributions and in the inclusion of noise in the data model. At our Institute, a neural algorithm for blind separation has been experimented on data sets simulating the Planck instrument output, giving good results for uniform low-level noise. Successively, a fast non-neural algorithm (Noisy fastICA) has been applied to separate the sources from the same data sets with a higher, but still uniform, noise level. The latter procedure is now under experimentation by astrophysical research teams in the Planck collaboration. We are now focussing on the modelling of nonuniform noise and the estimation of the source statistical distributions. We are experimenting with the recently proposed Independent Factor Analysis (IFA) approach for this purpose. Before estimating the data model, this technique learns a statistical source model, thus enabling a more accurate estimation of both the data model and the original source maps. An interesting feature of this approach is that prior information can be inserted easily into both the data model and the source distributions. This means that the IFA approach can be made only partially blind, since it is able to exploit both the simple independence and any additional information available, thus providing a better solution. Please contact: |