Mining Multimedia Documents by Visual Content
by Nozha Boujemaa and Marin Ferecatu
The IMEDIA research group at INRIA develops content-based image indexing techniques and interactive search and retrieval methods for browsing large multimedia databases by content.
Everyday, the average person with a computer faces a growing flow of multimedia information, particularly via the internet. But this ocean of information would be useless without the ability to manipulate, classify, archive and access them quickly and selectively. However multimedia is dominated by images, with respect to bandwidth and complexity.
The IMEDIA team achieves research, collaborations, and technology transfer on the complex issue of intelligent access to multimedia data streams. The prototype software IKONA illustrates this research lead at IMEDIA.
Specific and Generic Image Signatures
Visual appearance is automatically measured by numerical signature of image features such as color, texture, shape, or most often a combination of them. More specific image signatures have to be developed for special content and situations. For designing an effective image retrieval system, we find it convenient to divide image databases in two categories:
- The first category concerns specific image databases for which a ground truth is available. When indexing the database, the designer will consider these ground truths and tune the models or range of parameters accordingly, maximising the system efficiency. We have developped specific signature for face recognition and detection and fingerprint identification.
- The second category includes databases with heterogeneous images where no ground truth is available or obvious. Examples include stock photography and the World Wide Web. The user should be assumed to be an average user (not an expert). In this context, generic image signatures are computed in order to describe general visual appearance such as color and texture.
IKONA System Architecture
Our CBIR software IKONA, is based on a client-server architecture and aims to be flexible, easily extensible, easy to use, intuitive, and does not enforce special knowledge or training.
The server needs to be fast and is written in C++. It includes image feature extraction algorithms (signatures), user interaction policies (retrieve by visual similarity mode, relevant feedback mode, partial query mode, points of interest mode, etc...) and a network module to communicate with the clients.
The client needs to be portable and is written in Java; it normally should run on every computer architecture that supports Java Runtime Environment (JRE). It presents the user with an easy to use Graphical User Interface (GUI), sets the query mode for the server and display the search results.
The communication protocol is modular and extensible, ie it is easy to add new functionality (new feature extraction algorithms, searching methods, security access restrictions, etc) without disturbing the overall architecture (implementation). By default, IKONA does a ‘retrieve by visual similarity’ in response to a query, which means that it search all images in all databases and returns a list of the most visually similar images to the query image.
Interactive Search
In order to deal with generic databases, Ikona includes a relevance feedback technique which enables the user to refine their query by specifying over time a set of relevant and a set of non-relevant images. Relevance feedback interaction methods try to use the information the user supplies to the system in an attempt to ‘guess’ what are his intentions, thus making it easier to find what he wants. IKONA has a RF mode for category search in image databases, which means it can help the user to find more rapidly certain categories of images in large databases with browsing and user profiling methods. This interaction allow to compensate the ‘semantic gap’ in such image search system.
Region based queries are being integrated into IKONA. In this mode, the user can select a part of an image and the system will search images (or parts of images) that are visually similar to the selected part. This ineteraction allow to the user to precise to the system what part or particular object is interesting in the image. In this case, since the query is focused, the system response is enhaced with regards to the user target since the background image signature is not considered. We have developed segmentation based methods as well as point of interest methods to achive partial queries.
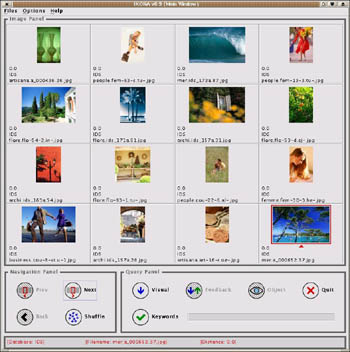 |
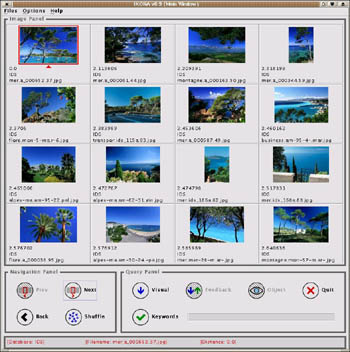 |
| Figure 1: Generic image database. Left: Selecting a query image in IKONA; the red border indicates the selected image. Right: Query results for the selected image. |
 |
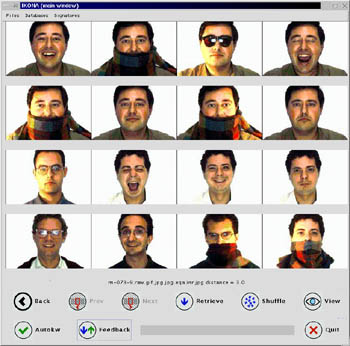 |
| Figure 2: Specific Image database. Left: Selecting a query image with relevance feedback mecanism in IKONA. Right: Query results for the selected image. For more results on face retrieval, see http://www-rocq.inria.fr/~sahbi/Web/ercim.html |
Hybrid Image and Text Indexing
While text indexing is ubiquitous, it is often limited, tedious and subjective for describing image content. Visual content image signatures are objective but has no semantic range. Combining both text and image features for indexing and retieval is very promising area of interest of IMEDIA team. We first work on a way to do keyword propagation based on visual similarity. For example, if an image database has been partially annotated with keywords, IKONA can use these keywords for very fast retrieval. Based on the indexed visual features and the keywords index, IKONA can suggest a number of keywords for a non annotated image and their weight. Further research on keyword propagation, semantic concept search and hybrid text-image retrieval mode are being carried on.
Short Term Involvement and Event
Several industrial partenership are going on: Judicial Policy for pedophilia problems, TF1 French Chanel with more efficency in TV journal preparation, France Telecom R&D, Thalès and Thomson Multimedia. IMEDIA has organized a first workshop of a series on multimedia content access management topic sponsored by NSF Digital Library Initiative with IBM (Watson research center) and Berkeley University. This workshop was attended by approximately 35 distinguished researchers from both academia and industry and from both Europe and United States. It provide a forum for active researchers in this area to exchange ideas on the most recent research progress and challenges in the area of multimedia content browsing, indexing and retrieval.
Links:
http://www-rocq.inria.fr/imedia/
Please contact:
Nozha Boujemaa - INRIA
Tel : +33 1 39 63 51 54
E-mail: Nozha.Boujemaa inria.fr inria.fr
|

