ERCIM News No.45 - April 2001 [contents]
ERCIM News No.45 - April 2001 [contents]
Similarity Hashing for Metric Data
by Claudio Gennaro, Pasquale Savino and Pavel Zezula
Similarity searching has become a fundamental computational task in a variety of application areas, including multimedia information retrieval, data mining, pattern recognition, machine learning, computer vision, genome databases, data compression, and statistical data analysis. This problem, which originally was mostly studied within the theoretical area of computational geometry, has recently been attracting more attention in the database community, because of the increasing need to deal with large, often distributed, volumes of data. Consequently, high performance has become an important feature of cutting edge designs. Scientists at IEI-CNR, Pisa, and Masaryk University, Brno, propose a novel access structure for similarity search in metric data, called Similarity Hashing (SH).
Similarity Hashing has a multi-level hash structure which consists of separable buckets on each level, supporting easy insertion and bounded search costs, because at most one bucket needs to be accessed at each level for range queries up to a pre-defined value of search radius. The number of distance computations is significantly reduced by use of pre-computed distances obtained at insertion time. Buckets of static files can be arranged in such a way that the I/O costs never exceed the costs of scanning a compressed sequential file. Experimental results demonstrate that the performance of SH is superior to available tree-based structures. Unlike tree organizations, the SH structure is suitable for distributed and parallel implementations.
We consider the problem from a broad perspective and assume the data to be objects from a metric space where only pair-wise distances between objects are known. Contrary to traditional storage structure designs where the I/O costs form the dominant component of the insert/delete and retrieval functions, the CPU costs in generic metric structures can also be quite high, as in some applications the computation of distances is time consuming. Our major objective is thus to develop a similarity search structure that would minimize both the I/O and the CPU costs. This has not been a major goal in previous studies which have tended to concentrate on main memory structures, not considering paged disk environments. The idea of reusing pre-computed distances at later stages, ie in the retrieval phase, seems to be promising. In this way, the number of necessary distance computations to evaluate a query can significantly be reduced and the search time decreased.
To the best of our knowledge, all metric data designs are trees, and the reported node utilization is typically poor (often much less than 50%). This implies high space occupancy and random access to read nodes. Note that sequential files can be allocated with the minimum of necessary disk memory, and the sequential scan of continuous disk areas is very fast. There are two additional reasons for arguing against developing metric structures as trees. First, insertion costs are high and node splitting strategies, both top-down and bottom-up, require a lot of distance computations - published articles do not usually report on this issue. Second, trees are not convenient for parallel and/or distributed implementations. On the other hand, parallel (distributed) memories are available and proper exploitation of their potentiality can significantly reduce the search costs.
The main challenge of our work is to build a similarity search organization based on hashed partitioning, that is the Similarity Hashing (SH) technique. This is a multi-level hash structure that takes advantage of the excluded middle partitioning. In fact, all buckets on a level are separable so that maximally one bucket must be accessed for any query up to a specific value of a query radius. Objects that at one level do not conform to such arrangements are excluded from storage on this level and become candidates for storing on the next level. Depending on the number of levels and the data file, some objects can be excluded, and are thus stored in a separate exclusion partition that must always be accessed. Once computed distances are memorised at practically zero storage costs - a distance between objects is a number. At query time, a computation of simple functions determines for each level maximally one partition to access. However, distance computation between the query and accessed objects is not always required. In fact, the knowledge about pre-computed distances can infer that the object does not belong to the query response set. To summarize, the main features of our approach can be characterized as follows:
- each object is stored through hashing in one bucket from the multilevel structure of separable buckets
- queries need to access maximally one bucket per level, plus the exclusion partition, and the number of distance computations is significantly reduced through pre-computed distances
- an upper bound of the number of accessed partitions is the number of hash levels plus the exclusion partition
- by storing the partitions in a sequential file and using the hashed structure as the main memory directory of its parts, the I/O costs are upper-bound by the costs of optimized sequential scan, but are typically much lower
- contrary to tree organizations, the SH structure is suitable for parallel and distributed implementations.
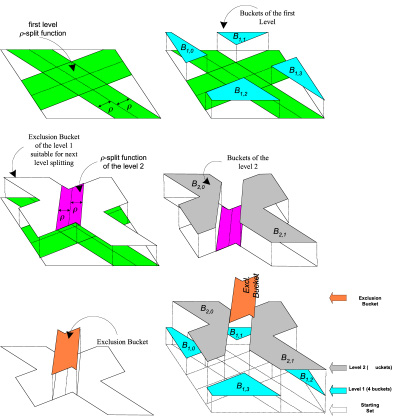
An example of creation of a two level SH structure. As can be seen on the figure, the SH structure is defined recursively. First, we define the r-split function of the first level. This function allows the objects of the data set to be spread among the buckets. The objects that are not accommodated in the buckets of the first level are reorganized in the second level, by means of second level r-split functions, and so on. Eventually, the remaining objects of the last level form the exclusion bucket.
We evaluated a prototype SH system and measured its performance in terms of the bucket reads and distance computations to solve range queries. We conducted our experiments on two synthetic sets of Euclidean vectors. The first set of experiments concerned 50,000 uniformly distributed vectors in 10 dimensional Euclidean space. The second set of experiments was conducted on 20 dimensional Euclidean vectors generated in clusters of equal sizes. We compared the search performance of the mvp-trees with the SH structure for the two different vector sets. The performance of the SH technique results from 5 to 25 times higher than that obtained when using the standard tree-based search structures.
Please Contact:
Claudio Gennaro - IEI-CNR
Tel: +39 050 315 2888
E-mail: gennaro@iei.pi.cnr.it