KALIF - Kernel Algorithms for Learning in Feature Spaces
by Bernhard Schölkopf
Kernel Algorithms represent a novel means for nonlinear analysis of complex real-world data. By providing a mathematical foundation for previous algorithms such as Neural Nets, they support systematic and principled improvements of learning algorithms for pattern recognition, function estimation, and feature extraction.
Learning algorithms are particularly useful in situations where an empirically observable dependency cannot be modelled explicitly, but ample empirical data are available. Examples thereof include pattern recognition problems ranging from pedestrian or traffic sign detection via internet text categorization to problems of financial time series analysis.
The KALIF project (Kernel Algorithms for Learning in Feature Spaces) develops and applies statistical methods for data analysis in nonlinear feature spaces. One can show that a certain class of kernel functions computes dot products in high-dimensional feature spaces nonlinearly related to input space. This way, a number of learning algorithms that can be cast in terms of dot products can implicitly be carried out in feature spaces - without the need for complex calculations in these high-dimensional spaces.
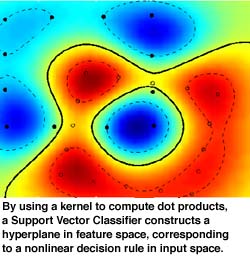
An example thereof are Support Vector methods for classification (see Figure) and regression. Moreover, we have recently generalized a standard algorithm for high-dimensional data analysis, the algorithm of statistical principal component analysis (PCA), to the nonlinear case. To this end, we carry out standard linear PCA in the feature space, using kernels. The algorithms boils down to a matrix diagonalization. It can, for instance, be used for nonlinear feature extraction and dimensionality reduction.
It is precisely the close encounter of theory and practice that renders this recently emerging research area particularly appealing: using complexity concepts of statistical learning theory and methods of functional analysis, we can now theoretically analyze and further develop a number of successful heuristical methods of data analysis. This has already led to record results on several benchmark problems, such as the digit recognition database of the American National Institute of Standards and Technology (NIST).
Potentially more important, however, is the fact that the increased accuracy of these algorithms helps opening up new application fields, which previously had not been accessible to machine learning such as, for instance, very high-dimensional data sets.
More information at: http://svm.first.gmd.de/kalif.html
Please contact:
Bernhard Schölkopf - GMD
Tel: +49 30 6392 1875
E-mail: bs@first.gmd.de
Klaus-Robert Müller - GMD
Tel:+49 30 6392 1860
E-mail: klaus@first.gmd.de