High-Performance Programming with Distributed Shared Data
by Simon Dobson
Many problems in distributed computing may be stated in terms of shared data for example a large matrix being generated by several parallel processes, or a document being written co-operatively by several people. Addressing these applications using low-level message passing places a unacceptable burden of complexity on the programmer, but allows highly efficient solutions to be developed; environments which provide distributed shared memory often improve the programming abstraction only at the expense of performance.
The goal of the TallShiP project a joint UK-funded research action between CLRC and the University of Leeds was to advance the state of the art in building distributed applications based on shared data by addressing the properties of such systems which lead to inefficiencies.
Shared Abstract Data Types
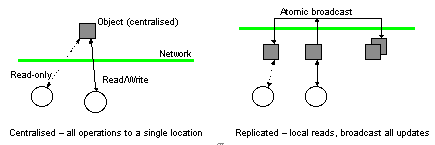
Most distributed shared memory systems adopt an object model in which the representation of objects is chosen from one of a small set of possibilities. These choices limit the scope for optimisation due to stylised patterns in the use of objects and enforce a single model of strong coherence on all objects. In many cases applications may tolerate weaker degrees of coherence, so that changes in a structure may not be immediately visible to all objects sharing it.
TallShiP has adopted a model of Shared Abstract Data Types (SADTs) which allows an object to be represented using any number of distributed implementation strategies. The programmer accesses the SADT through an abstract interface, and the exact representation of the SADT may be changed transparently to accommodate different usage patterns or coherence guarantees. This allows an SADT to deploy a number of important optimisations for example to improve the proportion of operations which can occur without network access without affecting the application-level code.
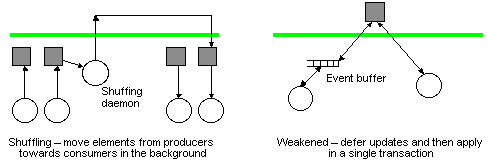
Some simple examples of this technique include moving data from 'mostly producer' nodes to 'mostly consumer' nodes in the background using additional processes (latency hiding), and applying a number of updates en masse to reduce network traffic. More complex examples create local caches of objects which are periodically refreshed and combination updates created using the known algebraic properties of operations. When used carefully, these optimisations allow shared data applications to approach the efficiency of explicit message passing algorithms.
An important aspect of the SADT approach is the use of a modified process algebra as a specification framework. This allows us to explore the effects that different representation strategies have on the detailed behaviour of a type.
Evaluation
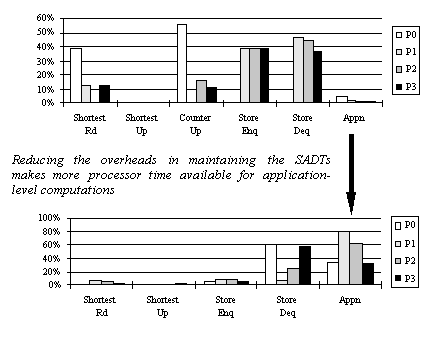
We have used the language Modula-3 to implement a prototype library of SADTs, each with a number of different representations. The effect of weakening and usage optimisation is to reduce the costs in maintaining the shared data abstraction. Essentially the weaker types are better suited to distributed representation than their stronger variants.
For example in a parallel solver for the Travelling Salesman Problem (TSP) a naïve implementation using centralised objects spends most of the processors' time in the shared data structure rather than in actually calculating the lengths of tours. By weakening the coherence model and tailoring the type representations to the actual pattern of use without changing the application code at all the cost of maintaining the SADTs is reduced dramatically.
This reduction in costs translates to speed-ups in the execution of such applications. For TSP on networks of workstations we have obtained speed-ups of 8 on 14 processors very acceptable for such a fine-grained problem and of 106 on 128 processors on a Cray T3D. More information on TallShiP at http://www.dci.clrc.ac.uk/Activity.asp?TallShiP
Please contact:
Simon Dobson - CLRC
Tel: +44 1235 445867
E-mail: s.dobson@rl.ac.uk