
ERCIM News No.24 - January 1996 - CNR
Analogy-based learning
and Natural Language Processing
by Stefano Federici, Simonetta Montemagni, Vito Pirrelli
The role and power of analogy in the acquisition and mastering of language has been largely neglected in recent linguistic literature. An explanation can mainly be found in the inherent difficulty of defining a formal setting for a rigorous evaluation of the power of analogy, which has thus been dismissed by most formal linguists as a woolly and at best unworkable notion. Nowadays, the general availability of computers with huge and cheap storage resources appears to offer an unprecedented opportunity for an algorithmic definition of analogy and for a scientific assessment of its role in Natural Language Processing applications. We discuss recent work in this area in collaboration with the "Istituto di Linguistica Computazionale" (ILC-CNR), Pisa.
Over the last four years, we have been developing in Pisa a variety of computational tools (e.g. in speech recognition and information retrieval) for the acquisition/analysis of Italian at different levels of linguistic description, all of which are based on a common analogy-based architecture. These tools have also been extended to the treatment of other languages (in particular English and French). Analogy-based self-learning techniques are competitive tools which combine the advantages of using language independent, tractable algorithms with the welcome bonus of being more reliable for real size applications than traditional systems.
Generalization by analogy can be defined as the inferential process by which an unfamiliar object (the target object) is seen as an analogue of known objects of the same type (the base objects) so that whatever properties are known about the latter are assumed to be transferable to the former. Correspondingly, by analogy-based language learning we mean the entire process of:
i) incremental acquistion of (unselected) base objects through exposure to an available repository of data (e.g. a training corpus),
ii) interpretation/generation of as yet unknown objects through generalization by analogy.
The assumption in i) represents an indispensable requirement for any self-learning algorithm intended to be psycholinguistically plausible: training evidence should not be carefully selected a priori to ensure convergence of the learning algorithm.
The requirements for an algorithmic definition of linguistic analogy are:
- a two-level description of linguistic objects (Figure 1), where a surface representation is associated with its interpretation (preferably in a "common currency" to allow exchange, integration and comparison with other parsing techniques)
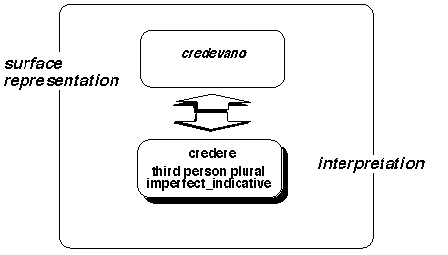
Figure 1: A two-level description of the morphological object "credevano" (they believed)
- a mapping function which identifies what two linguistic objects have in common
- a training data set, containing linguistic objects represented in a required format
- the network of analogical relationships holding among the acquired base objects as paradigmatically related patterns (see the paradigmatic structure in Figure 2)
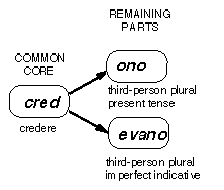
Figure 2: Core and remaining parts in a paradigmatic structure
- a best-match(es) identification function that projects the target object onto the network, to select the best analogue(s)
- a recomposition function (when needed) that pastes together (parts of) the best candidate analogues.
The definition of an appropriate mapping function addresses the crucial issue of establishing, for any pair of strings, the substring shared by both (the common core), and the remaining parts (Figure 2). In principle, the most appropriate mapping function should be as constrained as possible, while, at the same time, capable of identifying all linguistically relevant common cores. In practice, we have been trying to give priority to speed of mapping, under the assumption that an analogy-based self-learning system does not need to outdo an expert linguist in extracting a powerful linguistic generalization from only a couple of carefully chosen examples.
The general properties of our definition of analogy can be summarised thus:
- generalization by analogy is weak, as the mapping function is highly constrained (and linear in complexity) and core extraction is a non-recursive one-shot operation (no core-extraction cascade being permitted);
- generalization by analogy is quick, as a "once-found" analogy is a good analogy. As a result, generalization by analogy is a relatively passive process of registering and accumulating properties of linguistic objects by being exposed to a sufficiently large amount of them (i.e. a representative corpus);
- analogy is sensitive to properties that are relevant in the context of the intended application, as a common core is extracted between acquired objects only if they have in common properties pertaining to both their surface representation and their interpretation;
- the linguistic representation used to support the analogy is sufficiently general and theory-independent.
Our analogy-based engine is implemented in C and has been used in the context of the following applications: stress assignment (correctness rate 93%); phonological transcription (correctness rate 98%); morphological analysis (correctness rate 96%); morphological generation (correctness rate 75%); morphosyntactic tagging (correctness rate 95%); subject/object assignment (correctness rate 98%); resolution of morphosyntactically ambiguous subject/object assignments (correctness rate 74%); word sense disambiguation (extensive test in progress); metaphor recognition (development stage); information retrieval (development stage). Other applications are currently being implemented.
Please contact:
Stefano Federici, Simonetta Montemagni - Parola s.a.s.
Tel: +33 50 577459
E-mail: {stefano,simo}@ilc.pi.cnr.it
or
Vito Pirrelli - ILC-CNR
Tel: +33 50 560481
E-mail: vito@ilc.pi.cnr.it
return to the contents page