

by Maria Theresia Rolland
Research on natural language processing at GMD-Institute for Applied Information Technology has reached a breakthrough. We have shown how natural language processing can be fully automated. The key to this development are new insights into the structure of language.
Language consists of words, words that are related to one another. While humans manipulate words and their relationships uncon-sciously and as a matter of course, computers need to have an explicit description of the semantic rules that govern a meaningful process-ing of words. A method called logotechnique (= word processing) offers a solution to this problem. The method focuses on the word and is based exclusively on semantics. Semantics refers to the mental substance of language, which encompasses the syntax, because the syntactical structures are also something semantic. The method was conceived for German, but the principles carry over to all languages.
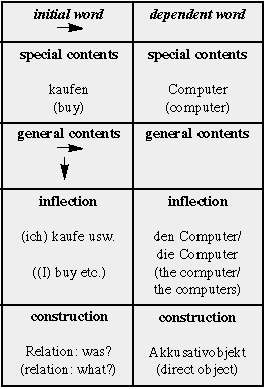
Each word has its individual contents. Even the contents of synonyms are slightly different. The contents of each word determines a set of dependent words. Those are words whose structure matches the given word, even if the set of these words may change over time as new words are introduced into the language. To say that the dependent word must match the initial word means that their special contents, i.e. the essential contents, must match. For example, Computer kaufen (buy computers) matches, *Erdbeben kaufen (*buy earthquakes) does not. Moreover, the general contents of the dependent word must match the general contents of the initial word. The general contents of a word are the contents that the word shares with other words of the same part of speech. The general contents consists of two parts: the first is the inflectional state of the word, here: accusative: "der Computer, die Computer" (the computer, the computers), the second is its constructional state within the phrase, here: "kaufen: was?" (buy what?). In this example the initial word is a verb, but the theory carries over to all parts of speech, such as nouns, adjectives, etc.
The words of each part of speech can be classified further according to similarities of contents. For example, the word "Gerät" (device) is a general term with subterms: Computer, Drucker, Diktiergerät (computer, printer, dictating machine) and so on. If "ein Gerät beschaffen" (purchase a device) is a meaningful expression, then "Computer, Drucker, Diktiergerät etc. beschaffen" (purchase a computer, a printer, a dictating machine etc.) are meaningful, too, due to the similarity of contents. Of course, classes of similar words may depend on various words, in our example "beschaffen, bestellen, leihen etc." (purchase, order, or rent etc.) would be possible.
While a class of similar words may depend on various initial words, each initial word has its own, unique set of possible dependent words; for example, on the one hand one can "Geräte, Bücher, Möbel etc. bestellen" (order devices, books, furniture etc.) and "ein Menu bestellen" (order a menu), on the other hand one can "Geräte, Bücher, Möbel etc. leihen" (rent devices, books, furniture etc.), but not "*ein Menü leihen" (*rent a menu). The classes of similar words are determined once; then they are generally applicable.
Besides, for each semantic relationship one needs to determine which inflectional state the involved words may have. These forms are also determined once and may then be accessed on demand.
By determining the set of possible dependencies in the language, one obtains the possible structures of relationships in a form that is used by humans when they speak.
For natural language processing, the possible structures of relationships are labelled specifically and result in the data structure of relationships. This structure can be used as a basis for applications ranging from query systems to full text retrieval, use of databases, and - most importantly - machine translation. Whenever a sentence is entered, the system extracts its semantic relationships in much the same way as humans do when they speak, by making choices based on the semantic relations in the data structure of relationships. The relationships can be identified automatically. Now the user is in a position to enter into a dialogue with the system.
The method is fully described in: M.Th.Rolland: Sprachverarbeitung durch Logotechnik, Bonn: D}mmler-Verlag, September 1994.