

Adaptive cancellation of the acoustic echo is essential to the perceived quality of any loud-speaking telephone system including video telephone and tele-conferencing equipment. In general the speech quality is optimized by combining the adaptive echo canceller with a voice control and careful acoustic design of the speech terminal. By splitting the speech signal into a suitable number of subbands, the computational complexity is reduced roughly by a factor equal to the number of subbands. When using conventional transform (DFT) or critically sampled filterbanks, the subband signals contain aliased frequency components disturbing the adaptive algorithm for updating the cancellation filters. This problem is overcome by introducing oversampling, that is by decimating the subband signals with a number less than the number of subband channels. This causes a penalty in complexity quadratically proportional to the oversampling factor.
SINTEF DELAB has cooperated with the Norwegian Telecoms Research lab (TF) in the development of a rationally oversampled filterbank with (near) perfect reconstruction. Rational oversampling factor allows for implementation of oversampling factors close to 1. This filterbank algorithm is used to implement a real time echo cancellation system, and is suitable for other applications such as audio and video compression.
The principle of acoustic echo cancellation
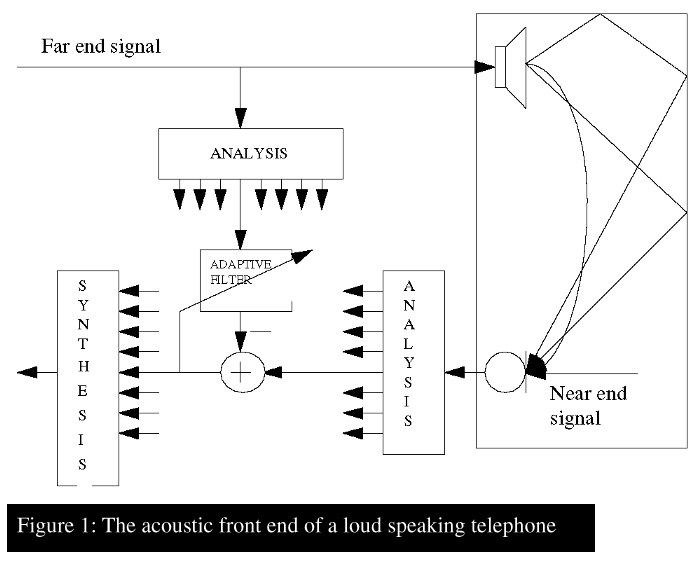
The complete acoustic front-end of a loud-speaking telephone is shown in figure 1. The far-end signal is fed through an adaptive filter forming an output to be subtracted from the microphone signal. The microphone signal is in general consisting of signals from three contributing sources. These are, the near end speaker, near end background noise and echo of the far-end audio signal originating from the terminal loudspeaker. The latter is an undesired component. Thus the objective of the adaptive echo canceller is to form a replica of the acoustic echo signal as picked up by the terminal microphone. This is achieved by inserting an adaptive filter parallel to the signal path through loudspeaker, room and microphone. The objective of the adaptive filter is then to provide a response as equal as possible to that of the acoustic signal path. Then the far end speech signal is fed through the adaptive filter to resemble the echo part of the microphone signal. The echo is then subtracted from the input audio signal to enhance the speech quality.
Practical concerns
As described so far, the echo cancellation system appears as a straight-forward realization of an adaptive filtering algorithm as the gradient-based LMS-algorithm (Widrow-Hoff) or a recursive least squares (RLS) approach. However, as many researchers have experienced, there is a lot more to it. One concern is the computational complexity for a full band implementation. As an example cancellation of 1/2 s echo response at 16 kHz audio sampling frequency involves filtering through an FIR-filter consisting of 8 000 taps working at 16 kHz, not mentioning the adaptive updating of 8 000 filtertaps. In addition the speech signal itself possess properties one has to account for in the adaptive filtering algorithms. The dynamic character of speech including intervals of complete silence is proven to be a problem in adaptive filtering. In addition the far from white spectral character slows down the adaptation speed causing long convergence time and making the system sensitive to changes of the acoustic room response. Finally the near-end speech and background noise if present also put demands on the system design.
As viewed from the adaptive algorithm the near-end speech signal appears as a disturbance. As this signal in general is and should be the strongest component it may cause large misadjustment to the filter taps. To overcome this problem an adaptation control algorithm is needed. In general such an algorithm is based on an analysis of the microphone signal
The sub-band approach
The idea of sub-band realization addresses two of the concerns as stated above. First the complexity is reduced by dividing the signal into subbands and applying adaptive filters to a decimated signal in each subband. Also the spectral variability within a subband is reduced as compared to the full band signal. To maintain transparency of the near end speech signal one will require the cascade of the analysis and synthesis filterbanks to provide perfect reconstruction. This simply means that the a signal fed through the analysis and synthesis filterbank system shall be an exact but delayed copy of the input signal.
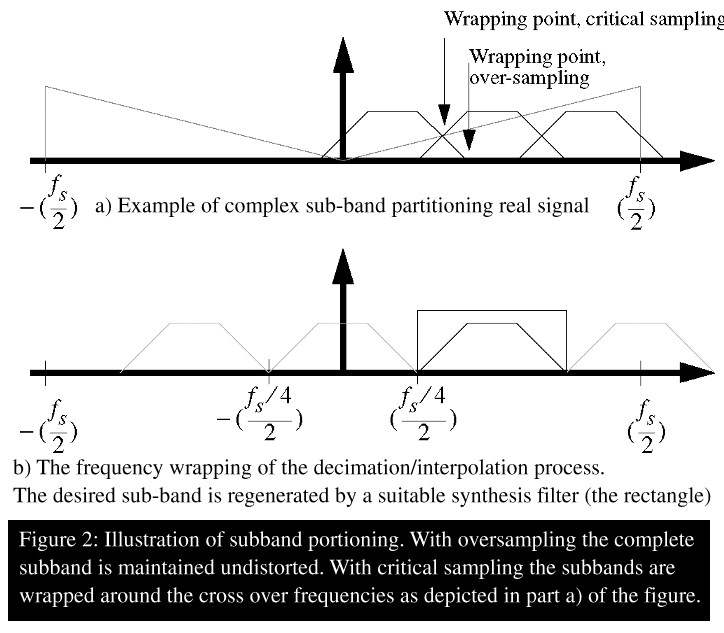
The intuitive first step to a subband implementation is to use a critically sampled filterbank. A finite length, discrete Fourier transform (DFT) can be viewed as an example of such a scheme. This approach will always imply spectral folding (aliasing) of the subband signal. The aliased signal components are disturbing the adaptive updating algorithm working in each subband and thus reduce the signal quality. One way to circumvent this problem is to introduce crosscancellation filters between adjacent subbands. This approach is shown to give only minor improvement of the signal quality. An alternative is to introduce oversampling in the subbands. This way the complete passband and transient band of the subband signal can be constructed to fall within the aliasing-free band of the subband sampling frequency. The principles of critical sampling and oversampling are illustrated in figure 2.
Of course some aliasing noise will still be present but in this case the aliased signal is due to signal leakage through filter sidelobes only. By proper filter design this leakage can be made much smaller than for the critically sampled case where parts the transient band will dominate the aliased signal components. A filter design based on oversampling by a factor of two is carried out and demonstrated in a real time environment.
However the price to pay for introducing oversampling is an increase in adaptive filter complexity by a factor equal to the square of the oversampling factor. This motivates for development of schemes with oversampling factor less than two which implies a non-integer oversampling factor. This can be implemented with a rational oversampling factor, for example by using 4 complex subbands (8 channels) and a decimation factor of 7 or less.
Design of a filterbank with rational oversampling and near perfect reconstruction
Motivated by the items as elaborated through the above discussion, we started a study of rationally oversampled filterbanks with perfect or near perfect reconstruction. We found very soon that a perfect reconstruction filterbank is always possible to implement with finite length analysis and synthesis filters but the synthesis filters turn out to contain a much larger number of taps than the analysis filters.
For equally length synthesis and analysis filters we have not been able to show the existence of an exact perfect reconstruction filter banks. However by developing an optimization routine we were able to design a filterbank with better than -60 dB reconstruction error and less than -50 dB aliasing noise within reasonable complexity and with an oversampling ratio of 4/3.
Status and further work
The project ended up with a real time demonstration of the system including a filterbank with rational oversampling. Possible extensions include industrialization of the system, alternative applications of the rationally oversampled filterbank, and further theoretical analysis of the design of rationally oversampled filterbanks.
{kind=link}
{kind=link}