
by Henk Nieland
Procedures to create lip-synchronous facial animations have been time consuming, costly and non-automatic. The central goal of the FERSA project (Facial Expression Recognition as a driver for real-time lip-synchronous Speech Animation) was to develop a means to automate this procedure for use in a television post-production environment. FERSA was sponsored by the Dutch Ministry of Economic Affairs and Valkieser Ltd, a post-production company in the Netherlands.
In contrast to much other work in this area FERSA doesn't put the emphasis on the synthesis of facial expressions, but on analyzing (sequences of) mouth shapes needed to produce a given text. Computer vision techniques were employed to automatically process and analyze video images of a narrator and to identify the necessary mouth positions needed to reconstruct a lip synchronous animation using the narrator's original sound track.
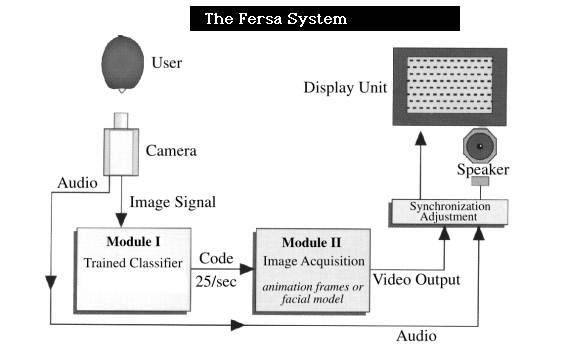
The developed system is composed of two main modules (Figure 1):
Module I is trained by having the narrator read a phonetically rich text in front of the camera. The images are analyzed and the narrator's characteristics are extracted for later classification of any general text input. If the training script is chosen correctly the system can be used for different languages. From research it appears that a small set of some 20 mouth shapes suffices to represent the basis set of mouth shapes necessary to reconstruct a convincing speech animation.
Module II, the reconstruction module, is presented with a string of indentifiers, analogous to a musical score, each identifier specifying a recognized mouth shape, one for every analyzed video frame. This module works in one of two ways, either the "flipbook" approach or the facial model approach. For the flipbook animation one only has to fetch images from some storage medium and to display them. In the facial model approach a parametrized model of some speaking entity is used. In this case, every recognized mouth shape is mapped to parameter settings for the facial model which then uses them to produce an image corresponding to the mouth shape.
To date the project has resulted in a tool which can greatly simplify the production of lip-synchronous animations. Possible further extensions are feature detection under varying lighting conditions without using make-up, and recognition of basic facial emotion expressions. These tasks will demand further research into the applicability of aspects including active contours, neural nets and optical flow analysis. This could lead to the construction of a tool for "performer driven" animations, or a tool for tele-conferencing on relatively cheap systems with low-bandwidth communication channels through image analysis at the sending side and image reconstruction an the receiving side.
Talking bottles
{kind=link}